DAI has invested heavily in integrating digital tools and approaches across our development work. This blog tells the stories of our digital development success stories, lessons learned, and opportunities to engage the growing digital development community around the world.
Lessons from Kosovo: How Multi-Stakeholder Coalitions Can Enhance Policy and Regulatory Frameworks for Cybersecurity
In early 2022, the Government of Kosovo, with the support of the U.S. Agency for International Development (USAID)’s Critical Infrastructure Digitalization and Resilience (CIDR) program, launched Kosovo’s Critical Infrastructure Cybersecurity Working Group (CICWG). This working group, led by the Prime Minister’s office and facilitated by CIDR, brings together stakeholders across the public and private sectors, academia, and civil society to discuss and recommend ways to bolster the cyber resilience of critical infrastructure.
Digital Safeguards: Synergy between Cybersecurity, Data Protection, and Human Rights in Moldova
Like so many other countries, Moldova’s digital transformation journey is fraught with challenges and opportunities. International human rights principles and regulations are highly valuable as the country develops its legislation, yet local engagement is crucial in understanding the specific needs and concerns of Moldovans and ensuring that digital transformation benefits everyone.
Overcoming Gender Biases to Support Cyber Workforce Development in North Macedonia
In my country of North Macedonia and elsewhere, cyberattacks on our essential services are becoming increasingly multifaceted and intricate. To defend against them, diverse teams equipped with myriad perspectives are key to comprehensive cybersecurity problem solving. This diversity, however, does not exist in the cybersecurity field; women—who represent half of technology users—comprise only 25 percent of the global cybersecurity workforce and only 11 percent of information security jobs among the European Union’s operators of essential services and digital service providers.
This disparity is concerning both as a matter of equity and security. A homogeneous workforce limits national capacity for cybersecurity problem solving. Furthermore, the underrepresentation of women in cyber career and academic pathways perpetuates gender stereotypes and may sway females from pursuing these pathways. When young women and girls see a field dominated by one sex, it can unconsciously reinforce outdated beliefs about what they can or cannot achieve. This stunts the growth of countries’ cybersecurity workforces by narrowing the talent pool.
Can Rural Digital Community Centers Be Sustainable?
This blog first appeared in ICT Works.
To bridge the digital divide, digital community centers—physical spaces that provide access to the internet, technology devices, and digital skills—have become a popular solution for organizations working to bring connectivity to remote areas. Not only do these centers bring internet access to previously unconnected communities, but they also deliver digital literacy training to equip citizens with the skills and knowledge to use technology for personal and economic growth while ensuring their meaningful and safe use of it. While these centers may benefit their communities and act as gateways to the digital world, a pressing question lingers: Can these centers become truly sustainable and self-sufficient?
In this post, we explore the lessons learned by digital community centers established under the USAID/Microsoft Airband Initiative, a public-private partnership that seeks to bring internet access to more women around the world. Partners of the initiative, including internet service providers (ISPs) and technology companies, have built and managed these centers in rural and semi-urban areas and pursued different models for sustainability. We’ll delve into the approaches the partners have pursued to keep community center doors open once initial financial support from the U.S. Agency for International Development and Microsoft ended.
Navigating Need and Want: 3 Ways to Create Demand Among Businesses to Safely Adopt Digital Tools
“A good beginning is half of the success.”—ancient proverb
As South and Southeast Asian digital economies rapidly expand, small and medium enterprises (SMEs) in the region face two dilemmas—both wrapped up in this one proverb. First, entrepreneurs can see the value of digital tools, practices, and infrastructure, but do they want to use them? Electronic payments, digital banking, and mobile applications clearly make business faster and more versatile, but not all business owners are ready to jump on the digital bandwagon. Second, businesses could adopt digital tools, practices, and infrastructure, but do they recognize the responsibilities that come with them? There are always benefits and risks of rushing to incorporate the latest online platforms.
Unveiling the Future: State of the Digital Agriculture Sector Report
In the ever-evolving landscape of agricultural development, the digital revolution has taken center stage. Digital tools have the potential to transform the agriculture sector, especially across low- and middle-income countries (LMICs).
The recently published “State of the Digital Agriculture Sector” report from Beanstalk, funded and sponsored by the U.S. Agency for International Development, DAI, and the Bill & Melinda Gates Foundation, delves into the current trends, challenges, and opportunities shaping the future of agriculture in the digital age.
North Macedonia Completes Cybersecurity Coordination Exercise
More than 30 members of North Macedonia’s government, critical infrastructure firms, and other key institutions recently completed the country’s 5th annual National Coordination Exercise and Cyber Drill.
Localizing Digital Public Goods
DAI is pleased to announce the release of its latest CDA Insights paper, “Localizing Digital Public Goods.”
Global donors and development implementers are increasingly aligned around the theory that digital investments are most effective and equitable when owned by local stakeholders who can leverage the full potential of digital technologies and data. They are also embracing an agenda of “localization” to prioritize local digital ownership, expertise, and leadership.
Social Media for Civic Education: Challenges and Opportunities in Cambodia
Abby Edwards, Aishwarya Jadav, Arin Kerstein, Alvin Siagian, and Shuyang Wang are second-year master’s students in the Johns Hopkins University School of Advanced International Studies international development program. They worked with DAI from September 2022 to April 2023 on the Innovations for Social Accountability in Cambodia (ISAC) project, implemented by FHI 360 and funded by U.S. Agency for International Development (USAID), to conduct an assessment of the Cambodian digital ecosystem and the digitalization of ISAC partner civil society organizations (CSOs). The team interviewed civic engagement experts, Cambodian CSOs working to implement the ISAC project, international organizations working in Cambodia, Cambodian content creators, and citizens in multiple ISAC target provinces. This post summarizes their key findings and recommendations.
Some Spider-Sense to Kick Off 20 More Years of Cybersecurity Awareness
This is the fifth in a series of blog posts about cybersecurity to mark Cybersecurity Awareness Month in October. This blog first appeared in the Tech Policy Press here.
“Spiderman,” as he was dubbed, worked for military intelligence as an undercover volunteer.
As told by Nathan Thornburgh in Time, Spiderman, later identified as Shawn Carpenter—a U.S. intel contractor by day—watched by night as hackers breached networks of the U.S. military and made off with uncommon stealth. Spiderman “clung unseen to the walls of their chat rooms and servers,” following the stolen files from site to site, landing him virtually in China’s Guangdong province. When his private-sector employers found out what he was doing, they fired Carpenter and stripped him of his top-secret clearance for “inappropriate” after-hours sleuthing.
Around the same time, in October 2004, a small nonprofit called the National Cyber Security Alliance, together with the new U.S. Department of Homeland Security, proclaimed the first National Cybersecurity Awareness Month. Their message: Update your antivirus software twice a year.
Safe to say, cybersecurity awareness has come a long way since Spiderman got sacked.
4 Key Takeaways from DAI’s Cybersecurity Programs in Southeast Asia and Mongolia
This is the fourth in a series of blog posts about cybersecurity to mark Cybersecurity Awareness Month in October.
Cyber threats in Southeast Asia are on the rise. Data from Singapore’s Ministry of Defense shows that cybercrime in the region increased by 82 percent between 2021 and 2022. To help counter these growing threats, the U.S. Agency for International Development (USAID)’s Digital Asia Accelerator (DAA) initiative, implemented by DAI’s Digital Frontiers under the Digital Connectivity and Cybersecurity Partnership (DCCP), promotes cybersecurity awareness and capacity building in Cambodia, Indonesia, Laos, Mongolia, Myanmar, and Thailand. Since 2019, DAA has implemented several cybersecurity awareness initiatives in the region. Drawing on these experiences, here are four of our key takeaways on how to create an enabling environment for better cybersecurity awareness, defense, and opportunity.
What Have We Learned in the Past Five Years about Cybersecurity?
This is the third in a series of blog posts about cybersecurity to mark Cybersecurity Awareness Month in October.
For digital development practitioners, cybersecurity is now in the digital development zeitgeist. Over the past five years or so, it has become an important standalone technical area, as well as a critical building block of all our interventions. In honor of Cybersecurity Awareness Month, I wanted to revisit Digital@DAI’s earliest posts about cybersecurity from 2018 to see how our initial thinking holds up against a 2023 mindset. Our first-ever series on cybersecurity introduced the concept of cybersecurity to digital development practitioners by doing three things:
- Providing a technical explanation of cybersecurity and linking it to the concept of trust;
- Examining cybersecurity through the lens of regulations, skills, and institutions, aligned to the World Bank’s 2016 Digital Dividends report, and;
- Examining the topic of pirated software at the micro level.
How Cybersecurity Literacy Can Help People Counter Disinformation and Exercise their Human Rights
This is the second in a series of blog posts about cybersecurity to mark Cybersecurity Awareness Month in October.
The 2022 Threat Landscape Report published by the European Union Agency for Cybersecurity (ENISA) highlights the spread of disinformation as one of the top eight cybersecurity threats. The U.S. Agency for International Development (USAID)’s Disinformation Primer defines disinformation as information that is shared with the intent to mislead people. As the world becomes more digitally connected and as digital technologies become more integrated into different aspects of daily life, it is important to understand the impact of digital disinformation. For example:
- Disinformation can cause people to stop trusting the institutions and systems that assist them in exercising their fundamental human rights.
- Citizens who do not trust their electoral systems will be deterred from exercising their right to vote.
- Business owners who are hesitant to use digital technologies will find it harder to earn a good income.
Unlocking the Potential of Generative AI in Cybersecurity: A Roadmap to Opportunities and Challenges
This is the first in a series of blog posts about cybersecurity to mark Cybersecurity Awareness Month in October.
Generative artificial intelligence (AI) is a fascinating field that is taking the world by storm. It is a cutting-edge technology that allows algorithms to create new and unique data, which was unimaginable just a few years ago. While traditional AI models are designed to recognize and classify existing patterns, generative AI models are trained to generate new patterns and unique output data. With generative AI, the possibilities are endless—MidJourney and DALL-E create art, and ChatGPT writes compelling pieces of text that are nearly indistinguishable from those created by humans.
Imagine the potential of this technology in industries such as healthcare and cybersecurity, where it can be used to create new and innovative solutions to existing problems. The possibilities are truly endless, and we are only at the beginning of this exciting journey. However, despite offering exciting opportunities and applications in cybersecurity, generative AI comes with its challenges.
Call for Sessions: ICTforAg 2023
Mark your calendars for November 7-9, because ICTforAg is back and bigger than ever. The recent online launch event unveiled the theme for 2023: “Cultivating Inclusion.” This annual gathering, now hosted by CGIAR in partnership with the U.S. Agency for International Development (USAID), Feed the Future, DevGlobal, and DAI’s Digital Frontiers project, will be a global hub where technology and agriculture intersect. Sign up now and submit your session ideas.
Government-Run Digital Tools to Combat Corruption: Can They Work?
(Originally published on DAI’s Developments blog.)
In 2014 and early 2015, more than 3,000 volunteers peered into their monitors to try and decipher poorly handwritten and scanned annual asset declarations from Ukrainian officials that described their properties, vehicles, land, commercial venues, bank accounts, and cash. It was a tedious task. At times, it seemed that civil servants deliberately used bad handwriting to comply with the requirements of paper-based transparency. By 2022, before the full-scale war, any internet user would have free access to more than 2.5 million asset declarations searchable through the public registry of the National Agency for Prevention of Corruption of Ukraine and at least one advanced civil society powered instrument that worked on the data-fuel from this registry. The difference was night and day. Now, instead of peering into illegible scans of handwritten scribbles, with a click of a button you can check whether a company owned by civil servant John Doe won any government contracts last year, and whether his elderly parents bought a mansion close to the capital or a new luxury car—and ask questions to the authorities.
Governments worldwide are rushing to use digital technology to reduce corruption. Over the past decade, state agencies have increasingly used digital systems to conduct anti-corruption investigations, gather and analyze asset declarations, automate electronic procurement processes, and analyze open data. Despite initial implementation difficulties in many countries, these digital tools have proven effective. Many governments that benefit from donor assistance are now asking to prioritize resources for upgrading or building new IT systems to help counter corruption.
What Do You Get When You Combine Digital Infrastructure, Skills, and Trust with Affordability and Device Access? Introducing Our Concept of Digital Readiness
DAI’s Center for Digital Acceleration (CDA) has done many deep dives about different topic areas on Digital@DAI over the years, from digital skills, digital trust, and digital infrastructure to affordability and access. For the first time ever, I am going to bring them all together under the umbrella of “digital readiness.” Before we get there, however, I want to acknowledge that CDA is not the first organization to come up with its own definition for this term. How have others defined digital readiness?
As Democracy Goes Digital, Cybersecurity Takes Precedence: 5 Critical Resources For Protecting Elections Against Digital Threats
From introducing biometric voter verification machines in Kenya to testing an internet voting pilot in Norway, election management bodies (EMBs) have increasingly digitized elections in efforts to increase efficiency, promote transparency, and encourage greater voter participation. While many elections have increasingly involved technology, including digital voter rolls, biometric voter registration, and electronic voting machines, these critical democratic processes have become more susceptible to a rapidly evolving threat—cyberattacks. Failure to address cybersecurity risks inherent to a digitized electoral process can pose a grave threat to electoral integrity.
Playing the Short and Long Game: The Importance of Adaptability in Cybersecurity Programming
Editor’s Note: This post is adapted from a lightning talk presented at the recent Global Digital Development Forum (GDDF) 2023.
Over the last few years, DAI has expanded its cybersecurity portfolio to cover regions including Asia-Pacific, Eastern Europe, and the Western Balkans. Designing and delivering programs that focus on building the resilience of cybersecurity stakeholders and ecosystems involves investments in three key elements of cybersecurity: people, process, and technology. It also demands that we apply this approach with local existing conditions. Importantly, cybersecurity programming also requires flexibility for rapid responses in case of unforeseen and new threats, political turnover, or major geopolitical developments expanding cyber or hybrid warfare. This is naturally dictated by realities and conditions in the geographies where we work, where local actors and beneficiaries often face external shocks requiring adaptation.

Photo: Stock.
Bridging the Gender Digital Divide: Four Approaches to Bringing Women Online From the USAID/Microsoft Airband Initiative
Globally, women are 18 percent less likely than men to own a smartphone. This statistic illustrates—particularly in low-income, rural households—the “gender digital divide,” where women are less likely to be connected to the internet and lack access to important tools that could improve their lives.
The gender digital divide limits women and girls’ opportunities on all fronts—from gaining an education to accessing their finances online to participating in politics and society.
Recognizing how digital inclusion empowers women and boosts the economies of rural communities, the USAID/Microsoft Airband Initiative has partnered with six private companies in five countries to provide women and girls with meaningful connectivity, internet access, and the skills necessary to navigate the digital world.

Photo: New Sun Road.
The Kids are Alright: Reframing “Digital Natives” for International Development
This post is adapted from a lightning talk presented at the 2023 Global Digital Development Forum (GDDF).
The term digital native was coined by Mark Prensky in 2001. The writer and educator used it to broadly describe a generation that grew up in an era shaped by the internet and digital technology. Digital natives are believed to possess a mastery of technological skills that are inherently different from prior generations. Prensky referred to the arrival of the digital age as a “singularity” that caused students of the time to “think and process information fundamentally differently than their predecessors.” These skills were attributed to the early introduction of digital tools into the homes, schools, and social lives of young people and the perception that this technology is seamlessly integrated into their daily interactions.
Toward More Transparent and Accountable AI Algorithms in Public Service Delivery: Insights from Brazil, Chile, Colombia, Egypt, Ghana, Kenya, Mexico, and Rwanda
From our social media feeds to the societal benefits we receive, artificial intelligence (AI) is everywhere and affects everyone. AI may assist us in a variety of ways: it can execute difficult, risky, or tedious tasks on our behalf; assist us in saving lives and coping with natural disasters; entertain us; and make our daily lives more enjoyable. AI helps doctors make decisions about our health and helps judges and lawyers sift through cases, speeding up the judicial process.
Governments worldwide are increasingly turning to AI algorithms to automate or support decision-making in public services. Algorithms assist in urban planning, prioritize social-care cases, make decisions about welfare entitlements, detect unemployment fraud, or monitor people in criminal justice and law enforcement settings. The use of these algorithms is often seen to improve efficiency and lower the costs of public services.
Frontier Insights Libya: Understanding Children’s Digital Access
Sesame Workshop and the International Rescue Committee (IRC) partnered to address the critical needs of children affected by the Syrian conflict and other crises in Jordan, Lebanon, Syria, and Iraq. The Ahlan Simsim initiative addresses the urgent needs of children affected by crisis and conflict by creating educational resources that reach children through an award-winning and impactful TV series viewed by more than 23 million children and through early childhood services that integrate media reaching more than 1 million children and caregivers in Iraq, Jordan, Lebanon, and Syria. Ahlan Simsim is exploring the possibility of expanding its work to other countries, specifically Libya.
Over the past 18 months, DAI’s Center for Digital Acceleration has been working with Sesame Workshop to explore the possibilities for using digital tools to provide education services to young children living in crisis-affected communities. Using DAI’s Frontier Insights™ methodology, in 2021 DAI conducted research in Yemen, Colombia, and South Sudan to understand communities’ barriers to connectivity, technology usage habits, and ways to leverage those habits to improve access to educational content.
In October and November 2022, the team continued its research in Libya, focusing on three locations: Khoms (east of Tripoli), Brak al Shati (south), and Tripoli Center. The local research team conducted surveys with 64 households, focused on children ages 3–8 and their parents or caregivers. In this blog we share the findings from that research.

Introducing Sesame Workshop’s Technology Decision Roadmap
There is no doubt that Sesame Street has produced an immense amount of educational media content for children. The iconic video of the Count von Count muppet teaching children how to count to ten permeates through American society. This value has expanded beyond the United States, providing globally accessible videos to numerous countries. Most recently, in 2022, Sesame Workshop, the nonprofit behind Sesame Street, created a library of newly produced, modular, play-based, and globally relevant animation videos called Watch, Play, Learn (WPL) to be distributed in humanitarian contexts and beyond. The 140 segments are five minutes each and cover thematic early childhood development areas: science, math, social-emotional learning, and health, safety, and child protection.
Lessons Learned in Bangladesh: Engaging Women in Digital Agriculture Tools
The role of women in agriculture is crucial, especially in countries such as Bangladesh where they make up almost half of the sector’s labor force. However, women often have limited access to resources and assets that could improve their livelihoods, including information that can be accessed through technology.
Digital agriculture tools, such as mobile apps and texting services, can help overcome the information disparity between men and women. But first, it is essential to understand the unique challenges that women face in agriculture and how digital tools can address those challenges. Women often have limited access to land, capital, and information, which hinders their participation. Moreover, they have limited mobility, which makes it difficult for them to physically access markets and other agricultural services.

Photo: BDAA.
The Digital Ecosystem Country Assessment (DECA) has Spurred Innovative Digital Development Around the World
In 2016, the Government of Colombia and the Revolutionary Armed Forces of Colombia (FARC) brokered a peace accord that ended nearly five decades of internal armed conflict. After years of reconciliation and peacebuilding efforts, however, new emerging threats to civil society, while digital, have the potential to incite physical violence, according to findings in a 2020 Digital Ecosystem Country Assessment (DECA) report published by the U.S. Agency for International Development (USAID) and DAI’s Digital Frontiers project. The report recommended that USAID invest in cyber hygiene programming in Colombia to assess and improve online and offline safety. Today, USAID Colombia has partnered with USAID’s Digital APEX project to build just this type of capacity.
As more USAID Missions like Colombia’s grapple with the emerging opportunities and challenges of our digital world, the Digital Strategy is shaping the Agency’s response. To design policies and programs that take advantage of technology, stakeholders need to first understand the building blocks of a country’s digital landscape. The DECA, a cornerstone of the Digital Strategy, is helping development practitioners to do just that.

Photo: Hanz Rippe/Paramo Films for USAID.
Preparing International Development Professionals for the Digital Age
This post originally appeared on the Center for Strategic and International Studies’ website.
Rapid advances in technology are transforming every industry in the global economy. In particular, the disruption created by the COVID-19 pandemic pushed governments, companies, and citizens to adopt a wide range of digital solutions. Many activities—including government services, work, schooling, and retail—shifted online. The pandemic also revealed that workers and regular citizens were not equipped with the right skills to operate in the digital age. A study conducted by the European Commission in 2021 revealed that only 54 percent of Europeans possess basic digital skills. In 2022, Salesforce’s new Digital Skills Index found that three out of four workers globally did not feel ready to operate in a digital-first world. Most worrisome is the fact that the same study revealed only 28 percent of respondents were actively engaged in training programs or pursuing learning opportunities to acquire digital skills.

Photo: FADEL SENNA/AFP/Getty Images.
Realizing Inclusive Connectivity in Liberia Through a Trusted Technical Engagement
Transmitting data through transparent fibers barely thicker than a human hair, the Africa Coast to Europe (ACE) optical-fiber submarine cable system revolutionized Liberia’s information and communications technology (ICT) sector. Landing off the shore of Liberia’s capital, Monrovia, in 2011, this 17,000-kilometer cable that stretches from France to South Africa marked the country’s introduction to high-speed internet. Providing connectivity to 24 countries, the cable also demonstrated a commitment to reduce the digital divide and democratize internet access in Africa through secure, diverse, and resilient ICT infrastructure investments.
While ACE, made possible through a landmark agreement between a consortium of telecommunications companies and member countries, significantly increased connectivity in Monrovia, the lack of optical fiber cables beyond the capital resulted in low connectivity in Liberia’s rural areas. Moreover, Liberia lacks a much-needed system of high-speed networks linked together with fiber-optic connections to establish what is formally known as a fiber backbone—a critical prerequisite to fully maximize the ACE cable’s potential.
A Call to Action: Igniting the Digital Revolution in International Development Studies
This post originally appeared on the Center for Strategic and International Studies’ website.
Technological advancements are transforming every sector of the global economy, opening the way for governments, businesses, and individuals to drastically reframe how they engage with one another. The field of international development is not immune to these changes and has, in fact, seen a marked shift in new approaches and business models in response to today’s digital age. Development practitioners are actively responding to the increased role of tools like artificial intelligence, digital identity, digital financial services, and geospatial visualization in project design and implementation. However, the increased use of digital technology also carries real risks to users. Beyond cybersecurity and data privacy breaches, the rise in disinformation and misinformation, the increased risk of misuse, bias, and discrimination, and the growing trend of digital authoritarianism around the world are all causes for concern.
Digital@DAI Year in Review: Top 10 Posts of 2022
As we do annually, it is time for the Top 10 Posts of 2022. What a year! A bit of a return to normalcy after the hardships of 2021, with a welcome return to childcare (not joking), in-person meetings, and travel to connect with colleagues and do technical work globally. In the digital development world, a continued reckoning with the complex challenges of advanced technologies and the multitude of benefits—and risks—of widespread digital transformation.
Happily, it seems our predictions for what we’re thinking about in 2022 were largely correct. Through Digital@DAI, we covered topics as varied as ethical artificial intelligence (AI) and its importance in international development, a robust series on digital literacy, and the disability divide in ICT. Interestingly, the top two most-read posts published in 2022 were climate tech-focused. Climate tech has been called the “new frontier for innovation and growth” and investments in the sector are at an all-time high. Our readers’ engagement with these posts aligns with the expanding focus on this area in digital development.
Chatbots for the International Development and Humanitarian Sectors: What Works?
You may have noticed chatbots becoming more commonplace in your life. Buying yourself a new sound system online? A chatbot pops up offering help. Need to confirm flight details? The airline’s chatbot can do that for you. Chatbots can offer a quick and easy way to get the information you need on the platform you are already using, whether that be a website, Facebook Messenger, or WhatsApp.
As they operate with low bandwidth and are simple to use, chatbots seem like they could be a beneficial technology to engage with recipients of our development and humanitarian programs, don’t they?
As with any technology, the use of chatbots is migrating from the private sector and becoming more prevalent in crisis and conflict response. However, documentation of lessons learned, successes and failures, and best practices of the use of chatbots in the development and humanitarian sectors are still few and far between. Through our work with Sesame Workshop, DAI conducted desk research and key informant interviews to examine use cases and review lessons learned for the use of chatbots in the international development and humanitarian sectors. In this blog, we summarize our key findings.

Image: Pixabay/Mohamed Hassan.
A Look Into the Future: Rwanda’s Road to Digital Transformation
A couple of months ago, my family was visiting me in Rwanda. We were traveling two hours outside of the capital, in a rural, forested area, on what seemed to be the only straight patch of road in the mountainous country. As we were admiring the landscape, in my rearview mirror, I saw a flash. I knew she got me. Sophia—one of Rwanda’s notorious traffic cameras (jokingly called “Sophia” by Rwandans and named after a humanoid robot that spoke at the Transform Africa Summit in 2019) cruelly captured me going over the speed limit. Within 15 minutes, I received a speeding ticket via text message. I quickly paid the fine through Rwanda’s mobile money app, MoMo, and we continued our trip. Despite the ticket, I had to marvel at the technology that underpinned the entire exchange.
In Case You Missed It—Discussing the Impact and Implications of AI on Digital Inclusion at the NetHope Conference
Last month, DAI’s Center for Digital Acceleration hosted a panel discussion during the NetHope Global Summit featuring artificial intelligence (AI) experts representing the public, private, and civil society sectors to discuss practical uses for facial recognition technology (FRT) and its impact on digital inclusion. The panelists presented specific case studies where they have seen their work intersect with AI and facial recognition technologies and digital inclusion, providing lessons learned for attendees to apply.
The Potential Value of AI—and How Governments Could Capture It, Part 2
Originally published on the McKinsey & Company website. Read Part 1 here.
Headlining, Part 2: How Misinformation Could Impact Development Programming
In December 2021, I wrote Headlining, Part I: Spreading Misinformation, which defines “headlining” as a form of misinformation that uses a sensational headline to uncritically pass along false information.
I also offered tips and tricks to avoid falling victim to headlining, like taking a moment to pause and ask yourself, “Does this sound too good or too awful to be true?” and actually reading a news article before you share it. Now I want to take headlining and situate it directly in the contexts and communities in which international development practitioners work.

Photo: Aman Pal/Unsplash.
The Potential Value of AI—and How Governments Could Capture It, Part 1
Originally published on the McKinsey & Company website.
Artificial intelligence (AI) could have a significant impact on individuals, businesses, and governments. Here is what countries need to know about its benefits—and the first steps toward realizing them.
The long-term potential of AI to change key aspects of the way we live and to support the operations of businesses, governments, and other organizations is hard to grasp.
Indeed, AI has contributed to improvements in quality of life for all segments of society through innovations such as predictive healthcare, adaptive education, and optimized crisis response. The National Health Service in the United Kingdom, for instance, set up a National COVID-19 Chest Imaging Database containing a shared library of chest X-rays, computerized tomography (CT) scans, and magnetic resonance imaging (MRI) images to support the testing and development of AI technologies to treat COVID-19 and a variety of other health conditions. Businesses have seen increased productivity and operational efficiency using autonomous robotics in manufacturing, AI-optimized supply chains, and intelligent cargo routing with autonomous vehicles, among other initiatives. For example, many logistics companies are using AI-powered sorting robots to optimize their warehouse operations. Governments can also harness the power of AI through personalized services and automated processes. Consider Singapore’s “Ask Jamie,” a virtual assistant that helps citizens and businesses navigate government services across roughly 70 government agencies through AI-powered chat and voice.
Digital@DAI Rewind: Is Intellectual Property Ready for Blockchain?
If you’re an avid reader of the Digital@DAI blog, then by now you’ve surely heard of blockchain technology. For those in need of a refresher, blockchain is a decentralized database system that records information in a way that makes it near-to-impossible to change, breach, or cheat the system. International donors and the private sector have deployed blockchain towards furthering financial inclusion, digital government, and improved supply chain management.
More recently, governments and the private sector are exploring how this technology can be applied toward the building of secure and data-preserving e-governance systems. Governments across the globe, such as in Chile, Estonia, Singapore, Uzbekistan, and Venezuela, to name a few, are using blockchain and other emerging technologies such as artificial intelligence, the Internet of Things and smart contracts to build digital governance systems. An exciting feature of blockchain is that it can support the creative industry by serving as intellectual property rights register and enforcement tool. For instance, the European Union Intellectual Property (IP) Office, in collaboration with participating offices, launched a Blockchain IP register, which has the ability to automatically store data about registered IP rights in various IP offices.
As blockchain is a versatile technology that impacts many sectors from cryptocurrency to creative industries and IP management, it is crucial that the digital development sector stays abreast of blockchain’s impact on digital transformation. This week, we will revisit a post from 2021 from Dr. Miriam Stankovich about blockchain’s applicability to patents, copyrights, trademarks, and industrial designs.
Digital@DAI Rewind: Right to Repair is a Development Issue
The “Right to Repair” is a concept and advocacy movement centered around the idea that anyone who owns a device, machinery, or piece of equipment should have the right to repair it themselves or take it to a repair person or shop of their choosing. While this has been a subject in tech news for the last several years, the concept is back in the spotlight. Last week, Apple unveiled its new, more repairable iPhone 14 and in June, the New York state legislature passed the United States’ first Right to Repair bill. With the movement picking up steam, we are reminded that there are linkages to our work in digital development. This week, we will revisit a 2021 post from Rob Ryan-Silva, Director of DAI’s Maker Lab, about why this movement is an issue the development community needs to care about.
Starting Now on Digital Transformation for Ukraine Reconstruction
Originally published on the ICTworks blog.
When the war in Ukraine comes to an end (hopefully with Ukraine having recovered all of its territories, including Crimea), Western countries are likely to provide a massive aid package to help rebuild Ukrainian infrastructure, buildings, and lives. This moment in history will offer an opportunity for Ukraine to engage in rapid digital transformation. We should already begin deploying digital tools that will help Ukraine as it continues to fight bravely against the invaders, with the intention of seeing the country emerge from war on the right foot for a quick recovery. As President Volodymyr Zelenskyy himself said the post-war reconstruction should use the moment to build “a new foundation for our lives: … accessible new technologies, best practices, new institutions and, of course, reforms.”
The Authentication Dilemma: Can a Single Solution Guarantee Security for Small Firms?
Due to the rapid rate of digitalization catalyzed by the COVID-19 pandemic, cyber-attacks have become ubiquitous, presenting opportunities to improve cybersecurity practices for small and medium-sized enterprises (SMEs). SMEs contribute up to 40 percent of the gross domestic product in emerging economies, make up 90 percent of all businesses, and provide more than 50 percent of employment worldwide, making them significant economic drivers and digital supply chain actors. They also endure unprecedented malicious cyber activity, such as ransomware, phishing, password targeting, and advanced persistent threat attacks. In Nigeria, cyber attacks against SMEs have increased by 89 percent, in 2022 alone, and in India, more than 60 percent of all SMEs experienced attacks last year.
Lack of Cybersecurity Talent Poses a Global Challenge and Opportunity
The limited supply of a skilled workforce is one of the major challenges plaguing the technology ecosystems of countries around the world. The field of cybersecurity is an excellent case study. According to the 2021 (ICS)2Cybersecurity Workforce Study, the cybersecurity workforce gap—the number of people needed to help organizations protect their critical assets from cybersecurity threats—is 2.72 million worldwide. Although down from 3.12 million the previous year, this is still a significant gap. The true shortfall is likely greater, as the study does not account for the public policy, diplomatic, or business talent in small and medium-sized enterprises. This post explores opportunities to enhance the cybersecurity literacy of policymakers, diplomats, and business leaders, and makes the case for cybersecurity workforce development across these professions.
Emerging eLearning Series: Accessible Training at Scale to Increase Local Governance Capacity in Libya
Since the beginning of the COVID-19 pandemic, DAI’s Center for Digital Acceleration (CDA) has been at the forefront of supporting international development projects to understand, apply, and implement eLearning solutions in settings that had not initially considered their wide-scale use.
This is the second in a series of posts that seek to capture some of these efforts, celebrate innovative successes, consider critical lessons learned, and support practitioners who continue to do this work.
Shaping History Series: Innovative Leaders Driving Digital Transformation—Interview with Neema Iyer
To put it simply, Neema Iyer is a trailblazer. Iyer is an artist and technologist influencing the digital development sector with her innovative lens on the intersection of data, technology, and design to improve government service delivery. The East African native is the founder and director of Pollicy, a feminist collective of technologists, data scientists, and creatives. After graduating with a master’s degree in global epidemiology from Emory University in Atlanta, Georgia, Iyer returned to Africa, where she was exposed to the lack of gendered perspectives in the information and communications sector on the continent. Simultaneously, she was also experiencing and witnessing frustrations at various touch points with the government, such as securing important documents, information, or services.
Artificial Intelligence in Healthcare for Development 4.0: Recommendations for Policymakers
Today, artificial intelligence (AI) is broadly understood to include not only long-term efforts to simulate the general intelligence humans exhibit, but also fast-evolving technologies—such as convolutional neural networks—that affect many facets of modern society, such as healthcare, national security, social media, agriculture, and more. The sweeping changes caused by AI have significantly increased the gap between government policy and innovative business models that rely on AI deployment. AI is changing norms and business models throughout society, demanding new and effective policy responses from governments on subjects with little real precedence. While governments struggle to adapt to the rapid pace of change, AI brings new solutions and offers the potential to transform how policy is made by providing new tools and methods of policy development.
Webinar Series: Connecting Innovators with Funders in Bangladesh
Identifying and facilitating linkages between those who own promising digital tools for the agriculture sector—better known as AgTech—and those who have funds to invest is key to supporting the long-term sustainability of scalable digital AgTech tools.
Panelists at a recent webinar unpacked exactly how these links can be accomplished. Hosted by the U.S. Agency for International Development (USAID) Feed the Future Bangladesh Digital Agricultural Activity, and the first in a series, “Scaling Digital AgTech: Building Ecosystem for Innovation, Investment, and Sustainability of Digital Tools in Bangladesh” featured panelists from business accelerators, venture capital firms, impact investment organizations, donor organizations supporting digital agriculture tools, and technology firms.
Improving Digital Literacy and Security Training In Cambodia: Suggestions for Funders, Training Providers, and Content Creators
Maura Joul, Annie Kemmerer, Baker Lu, and Billy Taki are second-year master’s students in the Johns Hopkins University School of Advanced International Studies (SAIS) international development program. They worked with DAI on the Innovations for Social Accountability in Cambodia (ISAC) project, implemented by FHI 360 and funded by U.S. Agency for International Development (USAID), to conduct a landscape assessment of digital literacy and security education and training initiatives in Cambodia. The team interviewed digital security consultants, content creators, training providers, local civil society organizations (CSOs), international organizations, and industry experts in Cambodia. This post summarizes their key findings and recommendations.
CSOs in Cambodia are experiencing rapid changes in response to COVID-19. The pandemic forced Cambodian citizens served by CSOs into the digital world, leading these organizations to shift their communications and programming to virtual platforms. Although Cambodian CSOs successfully aclimated to the rapid digitalization, the move to virtual has increased digital security issues in the country.

Photo: Unsplash.
Digital Literacy Series: Closing the Gap for Semi-Literate and Illiterate Populations
Last month, the Center for Digital Acceleration launched a series dedicated to digital literacy in international development. We want to learn more about this nuanced topic because digital literacy is central to sustaining the rapid digitalization that has taken place over the last two years. As donors, implementing partners, private companies, and government agencies invest in the digital transformation of key sectors and services, practitioners must prioritize helping the communities interact with digital technology “confidently, critically, and safely.”
Over the last year, I’ve had the pleasure of learning how international development projects can achieve this goal. While conducting research for the U.S. Agency for International Development’s (USAID) Digital Literacy Primer, I learned how important it is to design digital literacy activities that meet users where they are. A university student looking for an office job, a government official expected to adhere to new cybersecurity policies, and a farmer looking to use his mobile phone to diagnose crop diseases all have different contexts and needs that will shape how a practitioner supports a digital literacy journey. Recognizing the importance of developing unique strategies to serve these unique user groups, one question lingers in my mind: How can we support digital literacy among users who are not literate?
Before we dive in, are you new to the concept of digital literacy? If so, I highly recommend reading the first post of this series to learn more about the concept and how frameworks such as the European Union DigComp Framework can help development practitioners categorize the skills, knowledge, and attitudes needed to develop digital literacy. Another recent post, “Defining and Exploring Digital Literacy in Digital Development,” is also a helpful resource that shares how USAID defines digital literacy and how the USAID-funded Digital Frontiers program is incorporating digital literacy activities throughout its portfolio.

Photo: Images of Empowerment.
Embracing the Unlikely Resilience of Feature Phones
Most of us in the development sector have been preparing for an inevitable and imminent smartphone future. But in a recent article, the BBC highlighted an interesting—if somewhat unexpected—phenomenon in the world of digital devices: the “return of the dumbphones” (we prefer the less pejorative term “feature phones,” which we use in this piece). According to the article, “While sales figures are hard to come by, one report said that global purchases of [feature phones] were due to hit one billion units last year, up from 400 million in 2019. This compares to worldwide sales of 1.4 billion smartphones last year, following a 12.5 percent decline in 2020.” Some might argue that the feature phone has never really gone away.
4 Critical Considerations When Developing ICT Policies and Regulations
In a world dominated by rapid innovation, information and communications technology (ICT) is not only an accelerator for economic growth, it also provides on-ramps for vulnerable populations to participate in society and not get left behind. However, the potential of this type of tech can only go as far as a nation’s regulatory environment allows. A weak regulatory environment can drastically limit the benefits of ICT for a country’s economy, consumers, and citizens.
Emerging eLearning Series: Innovative Success for Children—A Look Into Oman’s Stemazone Initiative
This is the first post in a series that seeks to capture e-learning efforts, celebrate innovations, consider critical lessons learned, and support practitioners who do this work.
Flagged for Review: A Look at Hate Speech in the International Development Context
Many countries around the world recognize June as Pride Month—a time to celebrate lesbian, gay, bisexual, transgender, and queer (LGBTQ) people, while reflecting on the community’s history. But this year it’s not just sunshine and rainbows. In cyberspace, the discourse about LGBTQ people and their rights is increasingly crowded with hate speech. On any given day, my own Twitter feed is sprinkled with posts arguing that LGBTQ people are “grooming” children, claiming same-sex couples shouldn’t be represented in Disney movies, or attacking the validity and humanity of transgender people. While I find these messages deeply distressing, I’m forced to ask myself, “Is this hate speech?”
In this blog, I’m going to use the example of LGBTQ hate speech to lay out what hate speech is, link it to the international development context, and explore what social media platforms and other stakeholders are doing to combat hate speech.

Image: Unsplash.
USAID Launches Digital Government Model
In 2021, as people around the world—and their governments—were grappling with a rapid transition to digital technology, the U.S. Agency for International Development (USAID) Digital Frontiers project began working with the Technology Division of USAID’s Innovation, Technology, and Research (ITR/T) Hub to create a conceptual model of digital government, or e-government. That model is now live and available to the public.
Digital Literacy Series: The DigComp Framework
With the onset of the pandemic spurring ever-faster digitalization around the world, we at DAI’s Center for Digital Acceleration are thinking about the key elements needed to ensure sustainable digital transformation in the countries where we work. One of the primary building blocks needed to achieve sustainability is strengthening digital literacy. As digital development practitioners, digital literacy is a big part of our work. Whether a person is getting online for the first time or is a cyber specialist, we have a responsibility to ensure those we work with have the agency to use the appropriate technology meaningfully: to achieve professional and personal goals, while avoiding digital harm. We also have a responsibility to close the digital divide by supporting novices in developing basic skills, so they are not left behind.
How Four Awardees Are Paving the Way for a More Equitable AI-Powered Future
Introducing the Winners of USAID’s Equitable AI Challenge
Artificial intelligence (AI) tools are a dual-edged sword: they promise tremendous benefits for international development, but have also demonstrated instances of bias and harm, often resulting from inequitable design, use, and impact. Recognizing that AI technologies can cause gender biases, the U.S. Agency for International Development (USAID) urgently looked for innovative and creative approaches to address gender-inequitable outcomes by launching the Equitable AI Challenge in the fall of 2021. This challenge, implemented through DAI’s Digital Frontiers, sought to support approaches that increase the accountability and transparency of AI systems in global development contexts. Dozens of competitors submitted approaches related to the prevention, identification, or monitoring of bias and harm against women and gender-nonconforming people—reflecting the larger goals of USAID’s Digital Strategy, the National Strategy on Gender Equity and Equality, and the recently launched USAID AI Action Plan.
Drone Mapping Reflects Solid Waste and Ocean Plastic Impact of the Durban Floods
Heavy downpours over only two days in April 2022 caused South Africa’s worst and most deadly natural disaster to date: a flash flood so rare and devastating it has a one in the 300-year probability of recurring. According to the European Union, approximately 435 people died and up to 41,000 people were affected. Rescue and disaster response efforts, which began immediately, are ongoing.
How Can the Mexican Automotive Industry Capitalize on Data-Driven Global Value Chains?
Smart factories could position Mexico as an Industry 4.0 hub and open doors to data-driven global value chains (GVCs).
Mexico is embracing Industry 4.0. The digital factory in Puebla, the aerospace corridors in Querétaro, Guanajuato, Baja California, Sonora, Chihuahua, and Nuevo León showcase Industry 4.0 manufacturing throughout the country. Smart factories are facilities that primarily use automated tools and machines, from production robots to transportation devices or 3D printers. Products are equipped with sensors that allow them to connect and exchange data and communicate with each other. They make up a cyber-physical production system (CPPS) connected via the industrial Internet of Things (IoT).
Data are the smart factory’s blood vessels and the key enabler of modern global value chains (GVCs). In the networked smart factory, identities can be assigned to tools, machines, products, and materials. Items at each level of the GVC can thereby be precisely located and tracked. This networked and automated production environment is supplemented with “big data” (huge amounts of data from millions of nodes within a network, including the ability to process and analyze large amounts of data using cloud computing, artificial intelligence (AI), and machine learning). Data can be handled, processed, and analyzed in real time and passed on through GVCs. Greater customization is possible while retaining speed and efficiency. Individual products are networked and identifiable; customization is possible by drawing on user data, while customer data is directly transferred to machine data. Cloud computing and additive manufacturing enable decentralized production.
Apply Now: 2022 USAID Digital Development Awards
Have you used digital technology to promote locally led development? Have you safeguarded digital ecosystems by facilitating access to digital infrastructure for marginalized populations, securing internet freedom and human rights, exposing violent extremism, countering misinformation and disinformation, or strengthening cybersecurity?
Realizing Inclusive Digital Development Through Boosting the Digital Skills of People Living with Disabilities
Twenty-five percent of the nearly 1 billion people living with disabilities around the world live at or below the poverty line. Unfortunately, these roughly 250 million people are more likely to face obstacles ranging from finding employment to outright discrimination. However, digital technologies offer the potential to expand employment opportunities for people living with disabilities, allowing them to realize their capabilities, expand their networks, and increase their mobility through digital accessibility. DAI, implementing activities under the Digital Connectivity and Cybersecurity Partnership (DCCP), is designing activities that create employment opportunities and support networks for people living with disabilities in countries such as Cambodia and India.
Through its work with the Digital Asia Accelerator (DAA) and the South Asia Regional Digital Initiative (SARDI), DAI recognizes disability as a cross-cutting issue and strives to provide equitable access to digital tools for people with a wide array of abilities, including those who are hard of hearing, have visual impairments, speech impediments, or other learning, developmental, and psychosocial disabilities. DAI’s grantee organizations, consultants, and partners are making significant steps towards digital inclusion through the facilitation of trainings, workshops, and mentoring groups specifically targeted and tailored for people living with disabilities.
WomenConnect Challenge Blog Series: Strategy 5—Developing Community Support
This blog is part of the WomenConnect Challenge (WCC) Blog Series: Introducing Strategies for Closing the Gender Digital Divide. The U.S. Agency for International Development (USAID) WomenConnect Challenge is a global call for solutions to improve women’s participation in everyday life by meaningfully changing the ways women access and use technology. In the first round of the Challenge, WCC awarded nine grants to organizations working to identify and change the social and economic circumstances that keep women offline and under-empowered. Through close partnership with local awardee teams and community members, WCC has identified five proven strategies for closing the gender digital divide and increasing women’s empowerment. This blog explores one strategy at length.
In Bihar, India, Mahadalit women are regarded as the poorest, lowest caste and are often isolated due to cultural barriers, social norms, and rural location. Mahadalit women are also at high risk of becoming victims of rape or sexual harassment, often perpetrated by members of upper castes. The looming threat of violence, caste discrimination, and subsequent deprivation of social benefits and entitlements often silence and silo women, hindering their ability to self-advocate or come together to work for change.
Five Technology and Design Podcasts to Explore this Summer
As the weather gets warmer in the Mid-Atlantic region, I’ve been doing my best to get outside more during the day. Podcasts have been a pleasant addition to my walk, runs, and bike rides. Below are five can’t-miss tech podcasts that you should follow—all of which are insightful, engaging, and informative.
WomenConnect Challenge Blog Series: Strategy 4—Designing Creative, Women-Centric Technology
This blog is part of the WomenConnect Challenge (WCC) Blog Series: Introducing Strategies for Closing the Gender Digital Divide. The U.S. Agency for International Development (USAID) Women Connect Challenge is a global call for solutions to improve women’s participation in everyday life by meaningfully changing the ways women access and use technology. In the first round of the Challenge, WCC awarded nine grants to organizations working to identify and change the social and economic circumstances that keep women offline and under-empowered. Through close partnership with local awardee teams and community members, WCC has identified five proven strategies for closing the gender digital divide and increasing women’s empowerment. This blog explores one strategy at length.
Q&A: Drone Technology, Climate Adaptation, and Aerobotics—An Interview with Benji Meltzer
 Benji Meltzer is the co-founder and chief technology officer of Aerobotics, a South African ag-tech startup that uses artificial intelligence to support the world’s agriculture industry—specifically, farmers in managing their farms, trees, and fruits. We recently spoke with Benji on Aerobotics’ drone technology, the impact of digital tools in climate adaptation and mitigation, and more. This is an excerpt from that interview.
Benji Meltzer is the co-founder and chief technology officer of Aerobotics, a South African ag-tech startup that uses artificial intelligence to support the world’s agriculture industry—specifically, farmers in managing their farms, trees, and fruits. We recently spoke with Benji on Aerobotics’ drone technology, the impact of digital tools in climate adaptation and mitigation, and more. This is an excerpt from that interview.
Apply Now: Teach Digital Upskilling to Small Firms in Sri Lanka
Digital Frontiers’ South Asia Regional Digital Initiative (SARDI) is seeking applications from organizations to provide cybersecurity capacity building to small- and medium-sized enterprises (SMEs) in Sri Lanka.
SARDI aims to increase the digital capacity of the private sector and civil society through digital upskilling and by strengthening firms’ ability to engage in digital and ICT policy issues. SARDI implements activities focused on digital upskilling, policy awareness, and cyber capacity-building with entrepreneurs and small firms across South Asia.
WomenConnect Challenge Blog Series: Strategy 3—Cultivating Women’s Confidence
This blog is part of the WomenConnect Challenge (WCC) Blog Series: Introducing Strategies for Closing the Gender Digital Divide. The U.S. Agency for International Development (USAID) Women Connect Challenge is a global call for solutions to improve women’s participation in everyday life by meaningfully changing the ways women access and use technology. In the first round, WCC awarded nine grants to organizations working to identify and change the social and economic circumstances that keep women offline and under-empowered. Through close partnership with local awardee teams and community members, WCC has identified five proven strategies for closing the gender digital divide and increasing women’s empowerment. This blog explores one strategy at length.

WCC Grantee Viamo works to bridge the gender digital divide and bring vital tools and information to women in Pakistan. Photo: Viamo.
Getting Subnational: Combining Large Scale Surveys with Geospatial Data to Produce Better Small Area Estimation, Part I
Collecting granular location data on key socioeconomic indicators for strategic planning is an increasingly important topic in international development. Given the limitations of national-level data, many analysts and policymakers now focus on obtaining subnational data to identify pockets of poverty in a country, select priority sites for poverty alleviation programs, establish subnational benchmarks for monitoring and evaluation purposes, and cross-validate data collected by country governments on indicators such as child mortality and basic literacy rates.
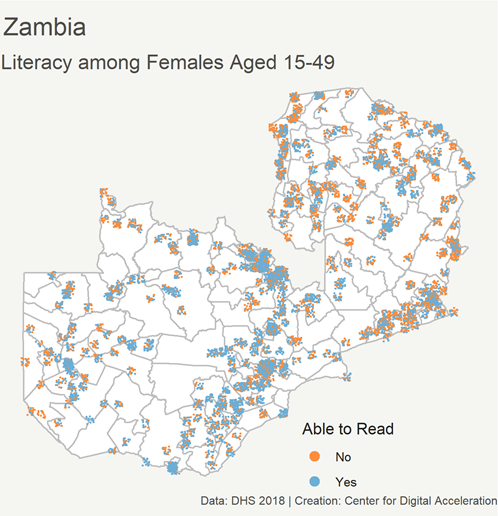
WomenConnect Challenge Blog Series: Strategy 2—Creating Economic Opportunities
This blog is part of the WomenConnect Challenge (WCC) Blog Series: Introducing Strategies for Closing the Gender Digital Divide. The U.S. Agency for International Development WomenConnect Challenge (WCC) is a global call for solutions to improve women’s participation in everyday life by meaningfully changing the ways women access and use technology. In the first round of the Challenge, WCC awarded nine grants to organizations working to identify and change the social and economic circumstances that keep women offline and under-empowered. Through close partnership with local awardee teams and community members, WCC has identified five proven strategies for closing the gender digital divide and increasing women’s empowerment. This blog explores one strategy at length.
It is no revelation that the global economy has been permanently digitized. Now, the internet is not just “the marketplace of ideas” but also the world’s largest marketplace of commodities, crafts, and services. Exclusion from this vast and dynamic market limits one’s opportunities in countless ways—socially and economically. Across the world, many women are unable to engage with the digital economy, and many “real life” economic opportunities—even those traditionally available to women—are moving online, rendering them inaccessible and necessitating new approaches to development.
Digital Trade in Southern Africa: How Firms Have Adapted to Digital Trade During COVID-19
Throughout the COVID-19 pandemic, companies in Southern Africa—like elsewhere in the world—have been forced to adapt to remote working: moving their business and communications online, conducting virtual business to business (B2B) meetings, and attending online trade expos and webinars. Between September and December 2021, DAI’s Center for Digital Acceleration worked with the USAID Southern Africa Trade and Investment Hub (USAID TradeHub) to understand how these businesses have adapted, what the long-term effects of the pandemic might be, and the support that firms need to adapt to the new normal. During this study, we spoke to three types of firms:
- Exporters: A firm—in the case of the USAID TradeHub, in Southern Africa—that sells its goods to a market other than its national domestic market.
- Buyers: An entity (firm, person, or association) that purchases goods from a vendor—in the case of the USAID TradeHub, the vendor is an exporter from the Southern African region. These firms may be based in the region or in the United States.
- Trade promotion service providers (TPSPs): An organization (public or private) that provides services to assist firms to trade—and in many cases, export—their products. Services include supporting firms to meet market entry and buyer requirements, supporting trade investment events where firms showcase their products and meet buyers, identifying demand and potential buyers and creating mutually beneficial relationships between exporters and buyers for long-term business.
The Path to a Sustained Network for Women Entrepreneurs in South Asia: Insights from the SARDI Strengthening Women in Tech Symposium
How do you take your chai or coffee? These opening words welcomed participants from all around the world for the South Asia Regional Digital Initiative (SARDI) Strengthening Symposium, a series of conversations about the most pressing barriers to investment in women-owned enterprises. Covering tremendous ground in 10 hours over four days, this virtual event connected finalists for potential partnerships, inspired applicants by clearly articulating the goals of the activity, and strengthened phase two applications in the process for the Strengthening Women in Tech in South Asia Initiative.
This SARDI initiative, implemented under the Digital Connectivity and Cybersecurity Partnership (DCCP),aims to address barriers for women entrepreneurs seeking to expand their business by connecting women across the region for peer-learning opportunities, providing mentorship, investment, and capacity-building support, and building awareness around the ICT policy environment that governs their businesses. The finalists participating in the symposium, ranging from large international organizations to consortia made up of local accelerators and industry associations, are in the running to ultimately design and implement this important regional network.
SARDI designed the symposium to bring together the best and brightest, selecting the top 10 out of more than 40 applicants.
WomenConnect Challenge Blog Series: Strategy 1 — Changing Social Norms and Cultural Perceptions
This blog is part of the WomenConnect Challenge (WCC) Blog Series: Introducing Strategies for Closing the Gender Digital Divide. The U.S. Agency for International Development (USAID) WomenConnect Challenge (WCC) is a global call for solutions to improve women’s participation in everyday life by meaningfully changing the ways women access and use technology. In the first round, WCC awarded nine grants to organizations working to identify and change the social and economic circumstances that keep women offline and under-empowered. Through close partnership with local awardee teams and community members, WCC has identified five proven strategies for closing the gender digital divide and increasing women’s empowerment. This blog explores one strategy at length.
“It can lead to stealing. Or promiscuous activities, drug abuse, rudeness, stubbornness, lies… 90 percent of the causes of immorality, bad behavior, attitudes of urban women are related to the internet.” This was one man’s justification for restricting his female family members from using the internet and mobile phones. “The internet will destroy their good upbringing and morality,” declared another young man. “We feel that the phone is a simple way to destroy a woman’s morality and alter her thoughts,” agreed yet another.
When WCC grantee Equal Access International (EAI) began its #Tech4Families program in northern Nigeria, baseline interviews were rife with this idea that women’s use of the internet and digital technologies would lead to their moral decline. At the baseline, 80 percent of men and boys interviewed did not believe the internet could be beneficial for women and girls, citing women’s use of digital technologies as immoral, inappropriate, or unnecessary. Many female interviewees echoed the sentiments of their male counterparts, perhaps having internalized the negative gender norms or fearing community backlash.
Digital Innovator Series: Discussing Entrepreneurship Ecosystems with Paing Hein Htet
Paing Hein Htet is a startup enthusiast and ecosystem builder from Myanmar. Paing has been working with innovators and startups across Myanmar for eight years, first by running fashion commerce and artificial intelligence startups, then through work in digital service design, and now as an investor. We recently spoke to Paing on strengthening digital ecosystems, the current state of entrepreneurial communities in Southeast Asia, and much more. This is an excerpt from that interview.
Global Insights from a Major New Study on MSME Digital Tool Use in Emerging Markets Amidst the COVID-19 Pandemic
The COVID-19 pandemic caused an unprecedented economic slowdown that had an outsized, adverse impact on micro, small, and medium enterprises (MSMEs) across the globe. As the world begins to reckon with the ‘new normal’ and countries take steps toward economic stabilization, it is clear that MSMEs—which account for two-thirds of employment globally and 80 to 90 percent of employment in low-income countries—will play an essential role in strengthening pandemic recovery efforts as they fuel economic growth and spur job creation in emerging markets. The pandemic also revealed the vital role digital technologies play in enabling businesses, communities, and individuals to connect, function, and thrive.
The Rise in Internet Shutdowns
Recently, a snowstorm knocked out the internet connection at my apartment. While I could still communicate with others from my cellphone and use 4G to check Twitter for outage updates, the temporary inconvenience highlighted how dependent my life is on reliable internet access and how vulnerable our day-to-day lives are when that access is unexpectedly taken away. For many individuals, especially those in countries with authoritarian governments, unanticipated internet shutdowns have become increasingly common.
The technical definition for an internet shutdown is when a government or nonstate actor intentionally disrupts access to the internet or certain platforms for a specific population or entire location to exert control over information. In 2020, Access Now’s Shutdown Tracker Optimization Project collected information on 155 reported instances of an internet shutdown, a significant increase from the 56 reported instances in 2016. As internet access has become more ingrained in a society’s ability to communicate, organize, and function, political leaders have increasingly leveraged their control of this resource to stifle dissent and reassert control.
Shaping History Series: Innovative Leaders Driving Digital Transformation—Dr. Joy Buolamwini
Aligned with the Center for Digital Acceleration’s commitment to fostering equity and inclusion within our team and the broader international development sector, Digital@DAI is launching a new series during Black History Month called Shaping History: Innovative Leaders Driving Digital Transformation. The series aims to spotlight racially diverse leaders in the tech space at home and in the countries where we work.
Without further ado, meet our first profile subject: Dr. Joy Buolamwini.
Apply Now: SARDI MSME Cybersecurity Awareness Campaign Design and Implementation
Digital Frontiers’ South Asia Regional Digital Initiative (SARDI) activity is seeking applications from organizations interested in conducting an awareness campaign for micro, small, and medium enterprises (MSMEs) in Bangladesh to help them improve their personal and business digital hygiene.

Photo: Pixelcreatures, Pixabay.
Apply Now: Help Assess Guatemala’s Digital Financial Services
Digital Frontiers seeks applications from firms to assess market conditions and identify gaps and opportunities in the use of financial services in Guatemala among low-income and marginalized populations, particularly women.
Low-income and marginalized populations, especially women, are more susceptible to shocks, whether economic, climate, or other, leading them to fall into poverty and sometimes migrate within or outside of their country. Often, individuals lack digital and financial literacy and skills, which prevents them from using financial services to help them better deal with shocks and build their resilience and incomes. This activity will better assess demand and supply-side market conditions to understand Guatemalan customer segments’ financial needs better. The partner will also develop a new or improved financial service prototype to target customer needs.
WomenConnect Challenge Blog Series: Introducing Strategies for Closing the Gender Digital Divide
“All technology has potential when modeled in the vacuum of our whiteboards and proposals,” remarks Revi Sterling, Director of the U.S. Agency for International Development (USAID)’s WomenConnect Challenge (WCC). Shrewdly cutting to the chase, Sterling adds: “[But] rural smallholder farmer women do not live in vacuums.” In other words: for digital technologies to be part of any development solution, practitioners must first address the myriad of real-life barriers and inequities surrounding technology use.
In her recent blog on the low uptake of digital agriculture applications by women, Sterling explains how digital development programming often fails to grapple with the inherent gender biases imbued in many software platforms and services. Many digital interventions also fail to investigate the unique social and cultural circumstances that may bar women from participation in the digital sphere. Social norms surrounding intersectional identities such as class, disability, caste, indigenous identity, gender identity, sexual orientation, language minority, and other factors can further intensify these barriers to technology access and use. These oversights in program or software design often unintentionally exacerbate poverty and inequality, deepening the gender digital divide and undermining the development effort’s good intentions.
Technology and Displacement: The Role of Digital Tools Among Displaced Persons
In a previous post from last March, I wrote about the reality of the gender digital divide, in which I noted the difference in digital access and usage among women and men globally and the lost potential that results from women’s lack of access. When able to access, understand, and leverage digital tools, women can use these tools to better their economic outcomes and those of their families and communities.
However, women are not the only group facing the reality of the digital divide. The United Nations Secretary-General’s Roadmap for Digital Cooperation, a report presenting strategies for inclusive, equitable adoption of digital technologies, notes some of the many other groups affected by similar challenges, including “migrants, refugees, internally displaced persons, older persons, young people, children, persons with disabilities, rural populations, and indigenous peoples.”
Apply Now: SARDI India MSME Tech Policy Fellowship Program
Digital Frontiers’ South Asia Regional Digital Initiative (SARDI) activity seeks applications from organizations interested in arranging one-year fellowships for up to five fellows in up to five different Indian think tanks.
Apply Now: Support USAID and the Bill and Melinda Gates Foundation to Assess the Implications of Artificial Intelligence and Automation on Employment and Inclusive Economic Development in Agri-Food Systems
As artificial intelligence (AI) and machine learning (ML) technologies advance and potential benefits continue to grow, much remains unknown on the long-term implications AI and ML will have on employment and inclusive economic development in agri-food systems in lower- and middle-income countries. Various studies conducted by global consulting firms predict a 14 to 16 percent increase in gross domestic product growth due to AI, with a significantly higher expected benefit for developed economies. With increased interest and investment in AI, the automation revolution appears to be driven and owned primarily by a small group of multinational companies, governments, and universities. By understanding who is likely to gain and who is likely to be left out, donors and governments can develop more responsible and inclusive programming that considers how these technologies will translate onto agri-food systems of the U.S. Agency for International Development (USAID) Feed the Future priority countries and the Bill and Melinda Gates Foundation’s (BMGF) focus regions.
Apply Now: ProICT Seeks Technical and Policy Advisory Support for ASEAN AI Research Brief and Roadmap
Digital Frontiers’ ProICT activity seeks a consultant or team of consultants to write a research brief and a subsequent artificial intelligence (AI) roadmap for member countries of the Association of Southeast Asian Nations (ASEAN). The research brief and AI roadmap will be shared at two convenings—or as required to incorporate substantive feedback and generate buy-in—and will be used to regularly and proactively solicit and incorporate input from relevant stakeholders. Proposals will be accepted from organizations, firms, or independent consultants.
Apply Now: Digital Inclusion Challenge Seeks to Advance Skills of Women-Led Firms Across Southeast Asia, Mongolia
Digital Frontiers’ Digital Asia Accelerator (DAA) is launching the Women’s Digital Inclusion Challenge to find partners across the Southeast Asia region that have delivered successful digital upskilling programs for women and micro-, small and medium-sized enterprises (MSMEs). The Challenge targets organizations looking to scale their operations to reach new countries and communities.
CDA Insights 2022: Toward Ethical Artificial Intelligence in International Development
When we conceived the idea of research on ethics and artificial intelligence (AI), we were—and still are—inundated with news about the detrimental impacts of AI from around the globe. Concerns about facial recognition technologies making false identifications and discriminatory hiring tools were amongst the many themes and headlines we saw. DAI’s Center for Digital Acceleration does its best to stay updated with the latest trends in technology and recognizes the benefits of automation and AI. However, these recent disturbing trends made it clear that the development sector needs to exercise greater caution when building and applying AI tools. AI is being adopted quickly in development, and we must act to prevent the adverse effects of these tools in the communities we work alongside.
Let’s Talk Fashion: How Digital Technology Can Support the Circular Economy
The fashion industry drives a significant part of the global economy. Valued north of $3 trillion, the fashion business—defined by the United Nations Alliance as clothing, leather, and footwear—accounts for 2 percent of the world’s gross domestic product. The sector responsible for employing more than 300 million people worldwide—many of whom are women—and providing goods indispensable to human welfare is also responsible for around 8 to 10 percent of carbon emissions, nearly 20 percent of global wastewater production, and about 9 percent of microplastic losses to the ocean annually. The circular economy in design that tackles climate change and biodiversity loss is based on three principles: eliminate, circulate, and regenerate. Although retail companies have increased their sustainable investments over the past five years, the progression remains slow in shifting to transparent and sustainable fashion standards.
While climate change threatens all populations, communities in low- and middle-income countries feel its impact first and worst. The onset of the COVID-19 crisis has powered global eco-awakenings; consumers are now, more than ever, urging fashion players to be more socially and environmentally responsible through all stages of the fashion production life cycle. While far from the target of taking urgent action to combat climate change and its impacts, digital technologies offer innovative solutions to tackling climate change.

Photo: Francois Le Nguyen/Unsplash.
5 Secret Sauces for Your Next Digital Safety Campaign: Insights from Thailand
In a previous blog on Five Fresh Tips to Make Digital Safety Cool Again: A Case Study from Thailand, we discussed lessons learned from implementing the ‘Wai Kid Digital’ Challenge, a series of virtual training bootcamps with university students on digital safety and creative video production. Looking back two months after the activity wrapped up, here are our top suggestions for your next digital safety campaign:
-
Build private sector partnerships that create shared value
-
Use hybrid approaches to engage Gen Z
-
Embed experience-based learning and networking opportunities
-
Localize your content to pave way for sustainability
-
Evolve your approach to capture the real story
The Digital Asia Accelerator, part of the U.S. Government’s Digital Connectivity and Cybersecurity Partnership, partnered with Facebook Thailand and Love Frankie (a local social change agency) to design and launch the Challenge. We then collaborated with nearly 400 university students around the country to demystify digital safety and educate the public about digital safety and identity, positive online communication, news literacy, and critical thinking through creative videos.
Looking Ahead: What We’re Thinking About in 2022
As we head into 2022 and reflect on two years of a global pandemic, new ways of connecting with colleagues and partners, and new areas of work, we at DAI’s Center for Digital Acceleration (CDA) feel as though we’ve been both sprinting and diving deep at the same time. The last couple of years gave us thrilling new work, new research areas, and opportunities to use both established and emerging digital tools in ways we could not have imagined. Below are five themes and trends that are likely to impact our work in 2022 and beyond. I welcome your additional thoughts and ideas as we explore these throughout the year on the Digital@DAI blog; tweet us at @DAIGlobal or email us at [email protected] to engage in the conversation!
.png)
Digital@DAI Year in Review: Top 10 Posts of 2021
As I do at the end of each year, I’d like to take the opportunity to reflect on the topics that were most read by you, our readers. This year had many ups and downs, from moments where we felt the pandemic might allow us to return to some sense of normalcy, followed by periods where we experienced continued isolation. The COVID-19 pandemic highlighted the continued importance of digital technology, reliable internet connection, and digital literacy as critical components to education, business, and family engagements. We’ve also seen the potential for the digital transformation that is underway around the globe to improve our lives and disrupt them.
Through Digital@DAI, we covered global trends in digital tool usage and key takeaways from work we are implementing globally. In total, we published 60 blogs that amassed more than 100,000 page views and covered topics from satellites for development to providing access to life-enhancing digital services.
In past years, we’ve summarized the top 10 posts of the year. This year, we noticed a pattern that I think is worth highlighting, especially given the renewed importance and pace of learning in the digital sector that the COVID-19 response requires. While readers enjoyed our most recent posts, our posts from previous years were quite popular, as well! Below, we feature the most read blogs published in 2021 and the most read blogs of 2021 overall.
.png)
The Hidden Costs of Online Shopping
I remember when my family first got an Amazon Prime membership. At the time, I was a freshman in college living on campus with no car. A trip to the grocery store was a half-day adventure involving multiple bus rides, weaving through weekend shoppers, and then lugging all my purchases back to my room. This all changed with two-day shipping. With Amazon, everything I could possibly need or want—ranging from toiletries and groceries to textbooks and school supplies—was at my fingertips with just a few clicks and two-day delivery. My half-day quests for essentials turned into a five-minute walk to the on-campus post office.
Building Resilience Against Disinformation
The proliferation of user-generated content enabled by improved connectivity and access to digital platforms is unlocking new economic opportunities, while also fomenting disinformation and falsehoods with potentially deleterious effects on society. Misinformation and disinformation can erode the trust and credibility of our public institutions, inflict financial harm, embolden nefarious actors, and jeopardize governance. While misinformation and disinformation are not new phenomena, the emergence of new digital platforms has enabled accelerated proliferation and reach, with implications across diverse sectors. Misinformation and disinformation can be omnipresent and not limited to politics, as they target value chains, consumers, and minority-owned businesses.
Meaningful Connectivity: Providing Access to Life-Enhancing Digital Services
A lack of digital connectivity is a prelude to exclusion in today’s rapidly changing world. Yet, more than 600 million people worldwide remain uncovered by mobile networks and broadband services. COVID-19 exacerbated the effects of this deep digital divide that continues to leave many communities disconnected, uninformed, and without access to life-enhancing digital services. Internet connectivity in the most remote places is essential to ensure that the most vulnerable populations do not get left behind. Moreover, these communities need effective connectivity that is consistent, safe, reliable, and accessible with enough bandwidth to allow for information access, news, government resources, telehealth, and educational instruction.

Women entrepreneurs accessing digital services in Guna, Madhya Pradesh, India. Photo: Digital Empowerment Foundation.
The AI Age Presents New Challenges in Cybersecurity
Artificial intelligence (AI) can be used to strengthen cybersecurity by detecting cyber threats more quickly and effectively. Imagine, for instance, if embedded malware meant to disrupt a hospital system’s operation was detected within minutes of its installation, rather than after it disrupted access to electronic medical health records, delaying medical treatments? In such a scenario, the use of AI to detect a cyber-attack could literally mean life or death. Despite these benefits, the use of AI also introduces its own set of cybersecurity vulnerabilities that bad actors can exploit. For example, it can amplify the exploitation of vulnerabilities across digital systems. Additionally, the use of Internet of Things (IoT) coupled with AI will further densify the potential cyber-attack surface.
Defining and Exploring Digital Literacy in Digital Development
Identifying and defining digital literacy can be challenging for even the most seasoned of digital development practitioners. “My previous work was very much related to digital literacy, but I didn’t recognize it as such,” shared Erica Bustinza, Project Director for the Digital Strategy Activity under the Digital Frontiers Project, which supports the U.S. Agency for International Development’s Digital Strategy implementation.
“After thinking about my previous work further, I would say over 50 percent of our team’s time and the project budget were focused on digital literacy efforts. Despite this, and my years of experience in digital development, I hadn’t ever considered that this was a ‘digital literacy’ project,” Bustinza reflected during the recent “What is Digital Literacy Anyway?” panel at the Global Digital Development Forum (GDDF).
Oftentimes, digital development programming necessitates the digital literacy of target populations, leading many initiatives to intertwine digital literacy activities with other technical programming to bring their overall objectives to fruition. Recognition of the breadth and depth of digital literacy efforts is crucial to advancing digital development worldwide.
Apply Now: Strengthening Women in Tech in South Asia
Digital Frontiers’ South Asia Regional Digital Initiative (SARDI) recently conducted a scoping study to explore barriers facing women in technology in South Asia, particularly those who are looking to scale and grow their businesses and engage on a regional level. A total of 47 in-depth interviews conducted in Bangladesh, India, Nepal, and Sri Lanka revealed a lack of mentorship and support for women entrepreneurs in tech. Interviewees mentioned a strong startup support ecosystem that fades away and leaves businesses lacking mentorship for growth over time and further investment opportunities. In addition, businesses lack the support required to navigate the myriad of digital policies that affect their business operations.

SARDI seeks to address these barriers through an initiative to connect women entrepreneurs in tech across the region and provide mentorship and capacity-building support to women seeking to expand their businesses. Digital Frontiers has released a request for applications (RFA) to develop this regional network and capacity-building program. As a result of this activity, women entrepreneurs’ digital capabilities will be strengthened, they will have a larger footprint in the digital economy, and an improved ability to engage in digital policy.
In Case You Missed It: Decoding Cybersecurity for MSMEs
A notification pops up on a business’s computer and says they have several days to pay an amount before all their data is deleted. This business just became a victim of ransomware—a debilitating cyberattack that can shut down entire companies and result in enormous financial losses. How do we protect businesses from experiencing these forms of attacks? DAI’s South Asia Regional Digital Initiative (SARDI), in partnership with the U.S. Agency for International Development (USAID)’s Indo-Pacific Office, recently hosted a thought-provoking webinar on strengthening the cybersecurity awareness, preparedness, and defense capabilities of micro, small, and medium enterprises (MSMEs) in South Asia. These businesses not only provide substantial employment opportunities in their communities but also contribute enormously to the region’s GDP levels. We felt it was necessary to bring together renowned experts from some of India’s most well-known technology firms as well as India’s Ministry of Micro, Small, and Medium Enterprises to address the region’s pressing cybersecurity risks, solutions, and resources. This webinar was part of the SARDI Dialogue Series of webinars highlighting the opportunities and challenges for South Asia’s MSMEs. SARDI is an activity under DAI’s Digital Frontiers project and part of the Digital Connectivity and Cybersecurity Partnership (DCCP).

Women entrepreneurs in West Champaran, Bihar, India. Credit: Digital Empowerment Foundation.
Headlining, Part I: Spreading Misinformation
We’ve all seen sensational headlines. Whether you find them through Twitter or via a WhatsApp group, headlines such as, “How Scientists got Climate Change So Wrong” (yes, that is a real opinion piece published in 2019 by The New York Times), are designed to provoke a strong emotional reaction in the reader and leave them with a false impression of reality. And while sensationalism in journalism is not new, the ongoing infodemic combined with declining perceptions of trust in news media and the cementing of social media users into echo chambers, creates a perfect storm in which headlining perpetuates misinformation. In this first of a two-part series, I’ll define the phenomenon, explain how headlining differs from “fake news,” and discuss five ways to spot and not fall victim to headlining.

Photo credit: Unsplash, Obi Onyeador
Digital Gaming Trends Offer Applications for International Development
Have you ever suffered the consequences of someone else’s online gaming habits? Maybe it was your college roommate playing World of Warcraft mere hours before your 8am exam, your partner choosing Call of Duty over date night, or your child’s “hidden” Candy Crush play under the dinner table as you tried to ask about their day. It is not unheard of for frequent gaming to negatively affect one’s ability to focus, productivity at work, or social relationships. In fact, in 2018, the World Health Organization even recognized “gaming disorder” among the addictive disorders included in its 11th edition of the International Classification of Diseases. Disorders are classified when the associated pattern of behavior results in significant distress or impairment in “personal, family, social, educational, or occupational functioning.”
RFP: Funding Available for Solutions that Address Gender Inequity in AI Technology
As the use of artificial intelligence (AI) proliferates, more instances of the inequitable design, use, and impact of AI-enabled tools in developing countries are coming to light. Many of these tools and approaches have the capacity for inequitable outcomes across genders due to humans unconsciously embedding bias in AI technology during data collection, model design or end-use applications. As a result, these tools often pose the greatest risk of harm and missed opportunities to those already marginalized in low- and middle-income countries. To foster an equitable and inclusive digital ecosystem, more efforts are needed to identify innovative and creative approaches to help decision-makers address actual and potential gender biases and inequitable outcomes resulting from AI technology.
New Multi-Country Research Explores MSME Digital Tool Use in Emerging Markets Amidst the COVID-19 Pandemic
As we approach the second year mark of the COVID-19 pandemic, the world continues to reflect on the stark realities the crisis has forced us all to acknowledge, including key drivers of economic resilience for individual businesses. As countries take steps toward economic stabilization, it is clear that micro, small, and medium enterprises (MSMEs)—which account for two-thirds of employment globally and between 80 and 90 percent of employment in low-income countries—play an essential role in strengthening pandemic recovery efforts. The pandemic has also revealed the vital role digital technologies play in enabling businesses, communities, and individuals to connect, function, and thrive. Ensuring that MSMEs can access digital tools is particularly crucial in emerging markets because MSMEs fuel economic growth and spur job creation.
GIS Data: Availability and Applicability, Part 1
It is an understatement to say that data are often imperfect. There are often holes, missing pieces that always seem to be precisely the required piece to cement the foundation of your carefully crafted research question. The process of massaging that research question will not be covered here, but data exploration is pivotal in discovering what is available and what is applicable, especially so when it comes to the spatial components of datasets. Hopefully, the following information will help you in the future when looking for data or deciding which spatial data to use to augment or drive your research.
Location-Based Platform Work Presents Benefits—and Risks—to Workers in the Global South, Part 1
One of the wonders of the digital age is that if at 11 pm I suddenly crave a pizza (Hawaiian preferably—no shame!), all I have to do is click a few buttons on my phone, and voila! pizza is delivered to my door. While it may feel like the pizza arrived by magic, especially given the “no-contact” options made available since the start of COVID-19, the satisfaction of my late-night craving is made possible by the work of independent contractors hired by digital platforms such as Uber and DoorDash to deliver products in cities around the world.
Apply Now: Support USAID and the Bill and Melinda Gates Foundation on an Assessment of Farmer-Centric Models of Data Governance and Ownership
As the number of digitally enabled agricultural products and services continues to grow in regions across the globe, most of the data collected by the digital service providers developing these tools remain locked within each entity’s systems. Due to incomplete, fragmented, or non-existent data sets on agri-food system stakeholders, such as farmers, digital service providers often take on the cost burden of collecting the information they need to develop products and services for their target users. This results in multiple actors holding fragments of information on agri-food system actors, decreasing incentives for data sharing across organizations and increasing the burden placed on food system actors to repeatedly provide their data to numerous researchers, companies, and development organizations. This dynamic has led to several missed opportunities for all stakeholders, including government agencies, the private sector, and the development community, to have a common and complete picture of the state of agricultural communities and the needs of individual actors therein.
The Future is Looking Up: Satellites for Development
When predicting which technologies might have an impact on international development in the coming years, shifts in the economics of a technology are often more indicative of impending transformation than improvements in its capabilities. Particularly in emerging markets, even older technologies can suddenly become disruptive once their cost drops, enabling wider application. With that lens in our spyglass as we scan the horizon for coming opportunities, then, we should not forget to look up, because satellites are getting radically cheaper.

Photo: Flickr, Paul Keller.
Study Shows Most Costa Rican Companies Depend on U.S.-Based Tech Platforms to Sell Goods or Services
Like much of the developing world, Costa Rica has limited availability of digital technologies compared to industrialized nations. Due to this lag in digital transformation, when the COVID-19 pandemic hit, commerce in Costa Rica was highly affected, leading to business disruption and unemployment. As of June, the country’s unemployment rate was 17.4 percent, which is an improvement upon the initial losses in 2020, however, still higher than the average for high-income countries (6.4 percent).
As COVID-19 stretches into its second year, formal companies, both big and small, are jumping into the digital world to find efficient and safe ways to offer their services and products online. Informal businesses are following suit, using online platforms to reach customers.

Photo: Unsplash.
Barriers to Digital Inclusion: What is Different for Children?
Throughout this past summer, DAI’s Center for Digital Acceleration has been working with the Sesame Workshop on its Play to Learn program to explore the possibilities for using digital tools to provide education services among children, ages 3 to 8, living in crisis-affected communities.
Frontier Insights Yemen: Understanding Children’s Digital Access
Throughout this past summer, DAI’s Center for Digital Acceleration has been working with Sesame Workshop to explore the possibilities for using digital tools to provide education services to young children living in crisis-affected communities.
Using DAI’s Frontier Insights™ methodology, our researchers in Colombia, Yemen, and South Sudan talked to children and their parents and caregivers to understand communities’ barriers to connectivity and their technology habits. Through this research, we sought to understand how technology might be leveraged to improve access to educational video content. In this series, we share our findings and interesting insights into the digital lives of children in these contexts.

Frontier Insights South Sudan: Understanding Children's Digital Access
Throughout the summer, the DAI Center for Digital Acceleration has been working with Sesame Workshop to explore the possibilities for using digital tools to provide education services to young children in crisis-affected communities.
Using DAI’s Frontier Insights™ methodology, our researchers in Colombia, Yemen, and South Sudan talked to children and their parents and caregivers to understand communities’ barriers to connectivity and their technology usage habits. Through this research, we sought to understand how technology might be leveraged to improve access to educational video content. In this series, we share our findings and interesting insights into the digital lives of children in these contexts.

Frontier Insights Colombia: Understanding Children’s Digital Access
Throughout the summer, DAI’s Center for Digital Acceleration has been working with the Sesame Workshop exploring the use of digital education tools for young children in crisis-affected communities.
Using DAI’s Frontier Insights™ methodology, our researchers in Colombia, South Sudan, and Yemen spoke with children and their parents and caregivers to understand their communities’ barriers to connectivity and tech habits. Through this research, we sought to understand how technology might be leveraged to improve access to educational content. In this series, we share our insights into the digital lives of children in these countries.

Bangalore and the Hidden Costs of ‘Silicon Cities’
Over the last 25 years, Bangalore, India, has transformed itself from a relatively sleepy second-tier city into a regional anchor for global technology corporations and a hub for innovative technology-driven startups. The international development community has cheered the growth of similar hubs in low- and middle-income countries—think Nairobi’s Silicon Savannah or Lagos. But Bangalore’s story often obscures the massive environmental and social toll that rapid, tech-driven growth can have on a city.
What is Agile? Part Two: A Primer on Different Frameworks
As discussed in part one of this series, agile is an umbrella term that encapsulates a number of frameworks, strategies, and tools. In this second installment, we dive a bit deeper into what agile is in practice by highlighting some of the most common frameworks used by agile teams. This primer on agile frameworks and methods will by no means be comprehensive (there are entire courses, websites, and certifications dedicated to each), but it can serve as a good starting point for better understanding which flavor of agile might be best suited to your teams’ needs if you are considering adopting agile in your organization. This post will cover two of the most popular types of agile in more depth: Scrum and Kanban. There are several others that are widely used as well, but these two have many components that can be flexible and adaptable for use in non-software development contexts.

Photo Credit: Unsplash
The Rise of TikTok: How One App is Making Waves in the Global Development Community
TikTok—the popular short video-sharing app—is now the fastest-growing social media platform on the internet. Rivaling companies such as Facebook, YouTube, Twitter, and Netflix, the controversial platform has amassed more than 2 billion downloads in more than 200 countries and 75 languages in just the past four years. And while the app has had success in diverse markets, its principles have been challenged by individuals and governments globally. In 2018, the Indonesian government enacted a one-week restriction on the app due to allegations of inappropriate content and blasphemy. The Indian government banned the app in 2020 on the grounds of geopolitical rationale. Former U.S. President Donald Trump attempted to ban TikTok due to U.S. national security concerns. Yet amidst these challenges, TikTok’s popularity continues to proliferate amongst diverse communities and influence international markets and the future development of domestic internet companies overseas.
.jpg)
Photo credit: Unsplash, Solen Feyissa
Is Intellectual Property Ready for Blockchain?
With its relatively low maintenance cost, increased transparency, reduced administrative burden, and resilience to fraud, blockchain is a versatile technology deployed in many sectors and businesses. So, what is blockchain, and could this disruptive technology have any application for managing intellectual property (IP) rights such as patents, copyrights, trademarks, industrial designs, and more?

Photo credit: Unsplash, Markus Spiske
Choosing the Right Digital Platform for Learning and Training Needs
As the world familiarizes itself with online learning in our COVID-19-affected times, we have been exposed to many seamless ways to experience remote learning. However, when we switch roles—from learning to developing different types of courses—this generalized exposure and all the technical terms for ways digital learning material is presented can become overwhelming. This blog explains the two most common platforms used to present eLearning material: Content Management Systems (CMS) and Learning Management Systems (LMS). Understanding these ways to structure and present eLearning material is key to determining which is more beneficial for a project’s needs.
Adults Teaching Children Digital Literacy in a Digitally Growing Society
Digital literacy goes beyond knowing how to create a TikTok account. True digital literacy is the ability to find, evaluate, comprehend, and use technology. Engaging with online content while simultaneously knowing the risks and limitations of technology is vital when participating in the digital world. Children today are using technology, now more than ever, to connect with peers and explore, search, and create content. Analyzing information, identifying patterns, and forming educated conclusions are invaluable digital skills for children to start building. Below are essential topics to cover when introducing children to digital literacy:
Blockchain: Are We Beyond the Peak of The Hype Cycle?
A combination of mainstream media attention and Elon Musk’s Twitter feed has reignited the public interest in distributed ledger technologies, commonly referred to as the blockchain. CDA is no stranger to this technology; check out our blog post on blockchain and how we’ve applied these concepts in-house. Blockchain-based applications leverage technology’s ability to decrease transaction costs, maintain immutable records, and provide users with privacy.
Over the last decade, international donors and the private sector have used blockchain across financial inclusion, digital government, and supply chain management. Recently, we revisited blockchain’s role in these various technical areas to assess its hype cycle and long-term deployment sustainability.
Can Regulators Keep up with Artificial Intelligence?
Artificial intelligence (AI) presents one of the most difficult challenges to traditional regulation. Three decades ago, software was programmed; today, it’s trained. AI itself is not one technology or singular development. It is a bundle of technologies whose decision-making mode is often not fully understood even by AI developers.
AI solutions can help address critical global challenges and deliver significant benefits; however, the technology could lead to unforeseeable outcomes absent clear regulations and ethical guidelines. AI can have damaging repercussions for data privacy, information, and cybersecurity, providing hackers with ways to access sensitive personal data, hijack systems, or manipulate devices connected to the Internet. Self-learning algorithms already anticipate human needs and wants, govern our newsfeeds, and drive our cars. How can we ensure that this technology benefits people widely? If AI and autonomous machines play a crucial role in our everyday lives, what sort of normative and ethical frameworks should guide their design?
Emerging Technologies Provide New Opportunities to Bridge the Digital Divide
New investments in emerging technologies offer transformational opportunities in developing countries—particularly for rural and remote populations benefiting from internet connectivity. This blog highlights three developments for potential donor interventions to work with the private sector, governments, and users to bridge the digital divide. These efforts may be complementary to planned or completed infrastructure, specifically for last-mile connectivity solutions to expand inclusive and affordable access for people across various regions.
Digital Asia Accelerator Cultivates Digital Skills for Cambodia’s Creative Sector
Widespread digitalization has revolutionized almost every industry, including music and sound production. While rarely the focus of digital development initiatives, creative entrepreneurs such as artists and musicians in emerging economies have also found themselves scrambling to adapt to the ever-changing technology and social media landscapes. As such, this year, with funding from the U.S. Agency for International Development (USAID)’s Digital Asia Accelerator (DAA) initiative and as a part of the Digital Connectivity and Cybersecurity Partnership, The Sound Initiative (TSI)—a vocational program for musicians—launched the “Music 4.0” program to support Cambodian entrepreneurs striving to excel in this dynamic industry.

Source: TSI.
New Report Offers Guidance to Support Agriculture Market Systems Actors During COVID-19
Digital tools and services such as short message services (SMS), digitally enabled extension services, and artificial intelligence have helped market system actors in developing countries overcome common challenges in the agriculture sector, such as accessing weather information and diagnosing pest or disease outbreaks.
Despite the documented value of these innovations, uptake of digital agriculture technology still is not widespread. A lack of affordable and accessible technologies, poor connectivity, high costs of data, and social stigmas around digital technology can be major barriers to potential users. With COVID-19 making digital connectivity critical to economic activities, development stakeholders have spent the past year and a half assessing the relationship between the pandemic and the adoption and use of digital agriculture.
Five Tools to Foster Creative Innovation
When we peel back the planning, strategy design, project management, and technical implementation layers of any creation, we see something more intuitive. More human. And that’s the desire to “create.”
Terms such as “innovation,” “research and development,” and “discovery” capture the adventure of the creative process. But garnering that same intensity in a workplace, let alone one’s personal life is not always the most accessible trail. In this post, I dive into some tools we employ as a team to foster creative innovation while also making reflections from another part of my life as a musician.
As a musician, I’ve gone through many periods of creative productivity. “Writer’s block,” as some may relate to, is the most frustrating. A quick online search generates tons of books on how to overcome creative dry spells. Meditation, exercise, and just taking a good ol’ break are some of the well-known remedies. But if there’s one thing I’ve learned from songwriting and performing, it’s that the creative process requires gentle nurturing. And just like music production, technology product development is no stranger to creative dry spells.
So, what are some of the tools we employ as a team to foster creative technology product development?
How Digital Climate Risk Assessment Tools Help Unclog Climate Finance Flows in Emerging Economies
Traditional lending channels are blocking access to climate finance. The large commercial banks that receive funds from investment banks accredited by the Green Climate Fund typically seek smaller financial institutions in local markets to distribute these funds. However, these smaller institutions often lack the tools needed to appraise risk and begin lending, meaning that funds that have been allocated towards climate mitigation, resilience building, and adaptation efforts are not being efficiently disseminated.
Reflecting on the Role of Digital Solutions in Tackling USAID’s Global Priorities
As most people in the international development community know, Samantha Power, former U.S. Permanent Representative to the United Nations under President Barack Obama, was nominated and officially sworn in as the 19th Administrator of the U.S. Agency for International Development (USAID) on May 3.
During her confirmation hearing testimony, she acknowledged the longstanding priorities of USAID that would remain at the fore, such as women’s empowerment, food security, education, and global health, but also cited four particularly pressing and consequential global issues on which USAID would focus in the years ahead:
-
The COVID-19 pandemic
-
Climate change
-
Conflict and state collapse
-
Democratic backsliding
Thinking about these priorities and what they mean for development work in the coming years, I thought about how digital solutions fit into this picture. Though not called out specifically in her testimony, digital technologies will serve a critical role in ensuring the success and effectiveness of these efforts.
Request for Information: Exploring the Role of AI and Automation on Agrifood Systems
Artificial intelligence (AI) applications are rapidly evolving to include more complex and advanced tasks. As a result, the number of meaningful use cases relevant to the development sector are expanding and demonstrate significant potential to solve some of the world’s most prominent challenges.

What We Learned From a Deep Dive into the World of Prizes and Challenges
A few months ago, our colleagues at the Digital Asia Accelerator buy-in under the Digital Frontiers project asked Alex Sekhniashvili and I to identify and synthesize lessons learned administering prizes and challenges across the U.S. Agency for International Development (USAID) portfolio. Given DAI’s long history implementing the Grand Challenges for Development Implementation Services, Center for Development Innovation (CDI) Professional Management Services, and Digital Frontiers projects on behalf of USAID—there are quite a lot of lessons! So Alex and I dove deep into the world of prizes and challenges, reading project documents and interviewing a number of DAI staff. Read below some of our findings.
Apply Now to Implement the Next ICTforAg Conference
ICTforAg 2020 engaged a global audience of 1,502 participants across 26 sessions over the course of one day. The conference examined digital solutions in agriculture as a means of fostering resilience in the wake of disruptions, from climate-related disasters to COVID-19, and the intersections between them. Building on the momentum of this global event, the Digital Frontiers team is supporting the U.S. Agency for International Development (USAID) Bureau for Resilience and Food Security in the next ICTforAg conference.

What Job Postings from Mexico's Energy Sector Reveal About the State of Clean Energy
A significant challenge to achieving the Sustainable Development Goals has been measuring country progress in the transition to renewable and clean energy sources. While expert surveys or legislation enacted may provide some insight into how countries are progressing on the whole, they lack the granularity to inform us about subnational trends, skills in-demand, and the presence of firms and subsectors within each country.
One useful way to explore these factors is by analyzing data available from job search engines and using keywords related to the energy sector. These can provide insights on how jobs in key sectors and subsectors evolve over time, what the demand for labor among firms in the energy sector is, where these openings and firms are located, and how they differ in terms of skills sought in the labor market.
Advances in ICT Connectivity Highlight Need for Digital Safety Preparedness in Pacific Communities
The Pacific Islands have the lowest rate of mobile internet penetration in the world and fixed broadband connection levels far below that of their neighbors. Recent and planned investments in building out undersea fiber optic cable and satellite services—including those financed by the United Nations, World Bank, and Asian Development Bank—are striving to change this, boosting internet speeds and expanding access to citizens, governments, and businesses across the region. In recent weeks I’ve spoken with a number of experts in the Pacific Islands about their concerns and priorities around this topic. Below are a few common themes that resonated throughout my conversations.
What Are We Reading about Technology and Ethics?
Tech ethics have continued to claim the public spotlight as more accounts of bias and harm due to technology and artificial intelligence (AI) have appeared in the media. Stories from racial bias in health care algorithms to gender bias in hiring algorithms have uncovered the lack of neutrality in technology that has previously been assumed to be completely objective and neutral.
Digital Innovator Series: Talking Girls in Tech with Voneat Pen
Kate Heuisler recently spoke with Voneat Pen, the Chapter Ambassador for Technovation in Cambodia, about her work growing the successful all-girl tech entrepreneurship education program for the seventh year in a row. While juggling her roles as the co-founder of the tech startup 606, a programmer, and STEM advocate, Voneat has been instrumental to Technovation’s success during its most challenging years. When COVID-19 pushed the program online overnight, the Technovation community (and its partners) were still able to successfully engage new all-girl teams, mentors, schools, and provinces across the country. To date, Technovation has helped connect more than 2,000 Cambodian girls to essential 21st-century tech creator skills.
This is an excerpt from that interview.
How Satellite Imagery and ‘Light at Night’ Helps Development Practitioners Estimate GDP
I am sure many of you have come across a map like the one below. I find that images of our planet are always awe-inspiring and this image is certainly not an exception. I can easily get lost in satellite imagery for hours if I am not careful. Most of those images are based on visual spectrum optical technology (LandSAT, Sentinel, etc.), thus requiring daylight for the powerful digital cameras to “see.” Remote sensing satellites such as VIIRS—which DAI uses for its analysis—are equipped with special infrared equipment and able to capture beautiful images of the earth at night!
Source: NASA and DMSP.
New Research Explores Digital Technologies and Their Impact on Social Accountability in Southeast Asia
Ian Cocroft, Karen Lee, and Connor MacKenzie are second-year master’s students in the international development program at the Johns Hopkins University School of Advanced International Studies (SAIS). The SAIS International Development (IDEV) practicum allows students to work directly with public, private, and nongovernmental organizations as a capstone to their graduate studies. Ian, Karen, and Connor worked with the Center for Digital Acceleration at DAI. The students conducted virtual research in Burma, Cambodia, Thailand, and Vietnam during the 2020-21 academic year to better understand how civil society organizations (CSOs) use digital technologies to support social accountability in public service delivery. The team’s final report provides DAI with considerations on how CSOs can better integrate digital technologies into their operations and highlights regional examples of digital tools for social accountability.
Our practicum team worked with DAI’s Center for Digital Acceleration on a regional study about how CSOs in Burma, Thailand, and Vietnam use digital technologies for social accountability in public service delivery, providing a series of recommendations for the U.S. Agency for International Development-funded Innovations for Social Accountability in Cambodia (ISAC) program. As part of our research, we undertook an extensive literature review and held Zoom interviews with country representatives from CSOs, tech organizations, and multilateral institutions.
Fast Company's World Changing Ideas Awards Highlight Opportunities for Digital Development
Fast Company magazine has been around for decades…but is it relevant for digital development work? The publication was founded in 1995 at a time when business was changing the world in new ways. Today, 26 years later, we are still coming to terms with the ways that technologies are transforming the ways we work and live—especially during the COVID-19 global pandemic. As I work with clients and projects focused on digital development, the businesses and organizations featured in Fast Company offer new ideas, inspiration, and out-of-the-box thinking to those of us heads down in global development projects.
This week, I wanted to share some of the winners of Fast Company’s 2021 World-Changing Ideas Awards—and how these innovations could apply to our work. World Changing Ideas is one of Fast Company’s major annual awards programs and is focused on social good, seeking to elevate finished products and brave concepts that make the world better.
Right to Repair is a Development Issue
Who owns the device you are reading this blog post on?
It may seem like a straightforward question until a power surge fries a key circuit or a stray elbow knocks a unit to the floor. At this point, the process of repairing what you thought was your (or your employer’s) property is likely to get a bit more complicated: The device turns out to be held together with proprietary screws, contains deliberately unobtainable spare parts, has software locks that cannot be overridden without the manufacturer’s express permission, or other random features included specifically to seal you out.

Source: TechSpot.
Apply Now to Support USAID Missions through Digital Agriculture Ecosystem Assessments
Despite the incredible progress made over the last decade by the U.S. Government’s global hunger and food security Feed the Future program, continued shocks, including the COVID-19 pandemic, make the work towards a more resilient global population and improved food security more relevant than ever. COVID’s impact on food security continues to be revealed but it’s estimated that 124 million more people experienced long-lasting poverty and hunger in 2020 and that 2.6 million more children will face stunting due to the pandemic. Across the globe, the U.S. Agency for International Development (USAID) is working to address these impacts.
My Transition from a Tech Company to DAI
Before joining DAI’s Center for Digital Acceleration (CDA), I worked in the software development industry. For the majority of my 15 years in this field, I only worked for tech companies whose main business model was building software. To successfully build software, there are multiple practices and skills that companies need. These skills are, for example, agile methodologies and good coding practices (such as patterns and documentation) that often vary from company to company and the type of technology used. Other practices include daily meetings and specialized resources for each phase of the software development process. In addition, there are roles such as back-end developers, front-end developers, DevOps, scrum masters, graphic designers, UX designers, and more! From this, you can see there is a lot that goes into making even a small web application. But, what I have just described is the experience of working on very large teams that only make software, which is very different from work within CDA’s Products team.
In Case You Missed It: The Digital Journey in South Asia—Opportunities and Challenges for Small Firms and Women Entrepreneurs
DAI’s Digital Frontiers Project, in partnership with the U.S. Agency for International Development (USAID)’s Indo-Pacific Office, recently hosted a thought-provoking webinar featuring views from the field in Bangladesh, India, and Nepal on opportunities and challenges for small and medium-sized enterprises (SMEs) and women entrepreneurs in South Asia. Our panel brought together diverse perspectives from experts in government, private sector, and civil society to discuss the key problems faced by SMEs in South Asia today and what the development community can do to break down barriers and help women entrepreneurs take their place as major players in the economy. Missed the discussion? Read the highlights below:

Photo Credit: Digital Empowerment Foundation.
We Urgently Need to Build Skills to Bolster Trust in Digital Tools
As part of last year’s launch events for the DAI Center for Digital Acceleration’s flagship Frontier Insights research on user perceptions of trust and privacy on the internet, two panels of experts helped underscore and widen the discussion around issues raised in the report. In the South Asia panel, a theme that emerged very clearly was the urgent need to build digital skills as a means to develop and maintain trust in digital services. Both the research and expert discussion highlighted the need for a multi-stakeholder approach to enable informed use and trust throughout the digital value chain.

Source: Global Citizen.
Knowledge Sharing in ICT4D: Beyond Internet Searches and Panel Events
As we head into “event season”—albeit remotely—I’ve been thinking about how we share knowledge about what we do in the ICT4D space.
In doing some recent research and sector mapping, I noted how different the levels of ICT4D development are amongst various sectors. In digital agriculture, it is generally accepted that there are numerous innovations out there and a plethora of pilot projects, but many are struggling to bring these innovations to scale. Many programs might be integrating digital as a pilot here and there, but struggling to identify what works and how they can reach the program goals. There are a huge number of initiatives seeking to share lessons within sectors, but how many are taking lessons from sector to sector?
Apply Now to Provide Digital Development Strategic Communications Support
DAI is searching for experienced organizations to offer strategic communications support to the U.S. Agency for International Development (USAID) through the Digital Frontiers mechanism. Digital Frontiers works with different USAID Missions and Bureaus in 37 countries. Its activities include: testing approaches to closing the gender digital divide; driving women’s economic empowerment and entrepreneurship; increasing cybersecurity awareness; strengthening ICT policy and governance; working on digital literacy and digital financial services; supporting capacity building within USAID; and integrating digital tools and technologies into agriculture programs.

Photo Credit: Equal Access International (EAI)
What is Agile? Part One: The Story Behind the Buzzword
Agile methodology has been a trending topic for a while now and it typically describes a wide range of approaches to software development, project management, and even raising children. Everyone loves to say they work on an agile team or to describe their company as an agile organization. While it’s true that its widespread use has changed the way people work, the details around agile have started to become diluted to the point where no one really knows what it means anymore. The Agile Alliance, an organization that supports those who use Agile, defines it broadly as “the ability to create and respond to change.” This post is the first in a series aimed at unpacking this buzzword and how the set of ideas it represents can be used effectively in international development contexts.
Five Fresh Tips to Make Digital Safety Cool Again: A Case Study from Thailand
Southeast Asia is one of the world’s fastest-growing regions for digital connectivity. Thai people, for example, spend on average nine hours a day using the internet on their mobile phones. That’s the second highest in the world! And 95 percent of all Thais connected to the internet use Facebook.

We have all heard about the dangers that come with using social media—misinformation, privacy concerns, and cyber bullying—just to name a few. But people in Thailand, like many places around the world, are still very invested in social media platforms, despite the challenges. So how might we turn this challenge into an opportunity?
The U.S. Agency for International Development (USAID) and DAI are collaborating with Facebook Thailand, Love Frankie, a local social change agency, and 400 university students around the country in the Wai Kid Digital Challenge to demystify digital safety and citizenship and educate the public about positive online communication, identity and security, news literacy, and critical thinking through creative videos.
Here are five fresh tips we have learned from the Challenge so far to make sure your next digital safety activity delivers results.
Going Virtual with Learning
For some professions, the past year has normalized virtual interactions and digital collaboration. While many jobs and activities still require in-person interaction, others have moved online as much as possible. Conferences are virtual. Weekly meetings take place through a screen. And classrooms have gone online.
Most people who have engaged with learning this past year have had some kind of digital experience. This is true across all ages—and, we have seen, often with mixed success. Nevertheless, at our Center for Digital Acceleration, we know that, as the saying goes—“the show must go on”—and we have done our best to help DAI’s projects around the globe make their in-person courses and activities come alive in our virtual world. In this post, we offer some brief reflections on the different types of online training our projects are developing, and then ask the question: is this the new normal?
In Honor of Women’s History Month: Exploring the Gender Digital Divide
With March being Women’s History Month, it feels appropriate to reflect on progress made towards the United Nations’ Sustainable Development Goal No. 5: Achieving gender equality and empowering all women and girls. Over the years, development programs have made significant strides in recognizing and alleviating the inequality that exists between men and women worldwide, though there is still much to be done. From DAI’s Center for Digital Acceleration’s perspective, it is particularly important to highlight the disparities that exist in the realm of digital tools and opportunities. In today’s world, where access to the internet and digital applications is increasingly valuable for both personal and professional purposes, female empowerment efforts must include the prioritization of women’s digital access, literacy, and inclusion.
What Are We Reading about Digital Transformation and COVID-19?
I find it difficult to use the word in this context, but there may be one positive—if not collateral—effect of COVID-19: after the decades of support the digital development community has provided to businesses and consumers around the world to help, the adoption of digital technologies has accelerated in mere months. There’s a new willingness to embrace the digital economy, as restrictions against in-person interactions move people online and require the use of digital tools out of necessity. This process, often called digital transformation, has been discussed by a variety of sources, outlining both its benefits and risks. We thought it might be helpful to provide an overview of some of the articles, blogs, and resources we are reading to leverage this momentum. This list is by no means exhaustive, but rather provides a few highlights to get you started. I’ve broken down the readings into three, highly academic categories: 1. This is really happening, 2. and the benefits could be huge, 3. but please do not forget the risks.
Why Electronic Waste is Relevant for the Digital Development Community
I was recently cleaning my house when I came across three old mobile phones: a feature phone, a BlackBerry, and an iPhone. I found myself wondering, “Why did I keep these?” Immediately, I thought, “the pictures,” but then quickly remembered that nowadays when everything can be saved to the cloud, that justification makes no sense. When I finished organizing, I found that I had left the three phones on my desk, as if they were patiently waiting for me to do something with them. It quickly dawned on me that I actually did not know what to do with them… not from a sentimental perspective, but rather from a lack of knowledge of how to securely dispose of technology. Shouldn’t many of the pieces and parts be reusable to build new devices or maintain old ones? Is there an equivalent to an electronics recycling bin?
Digital Innovator Series: Talking About Online Campaigns for Change with Sotheavy AT
We recently spoke with Sotheavy AT, the Founder of Think Plastic, a hugely popular digital environmental advocacy campaign working to reduce plastic waste and inspire action from citizens across Cambodia. (She’s also the former Senior Innovation Program Manager for the DAI-led Development Innovations, funded by the U.S. Agency for International Development (USAID) and a consultant on DAI projects across Southeast Asia.) Think Plastic started small, with two- to three-minute videos in 2019, and has grown rapidly to reach more than 4 million Cambodians in just one year—almost 25 percent of the population of the country. As more businesses, organizations, and citizens go online around the world in the COVID-19 era, we have seen evidence of how well-designed and well-executed online campaigns can rapidly advance development outcomes. Think Plastic has been widely recognized for its success by the Royal Government of Cambodia’s Ministry of Environment and the Women of the Future Southeast Asia and is now a well-known brand across the country. This is an excerpt from that interview.
Digital Development for Newbies, Part 2: Sophomore Edition
This month I’ve been reflecting on all that has happened since this time last year, back when we were still blissfully unaware of the trials, trauma, and transformation 2020 would bring. Instead of focusing on the challenges we faced over the last several months, I’d like to highlight some relevant concepts for colleagues who are gaining momentum in understanding and incorporating digital technologies into their international development work. Below are some important topics (upon which my tech-savvy colleagues and others have written extensively, so check out the links!) that can be applied across our development projects and fieldwork. Consider this the sophomore edition of the “Digital Development for Newbies” series, but if you’re brand new to this topic, I encourage you to start with Part 1: The Basics.
What Are We Reading about Misinformation and Disinformation?
After the insurrection/uprising/riot/attack/craziness/failed coup attempt (take your pick) at the U.S. Capitol building a few weeks ago, misinformation and disinformation are back in the news with a vengeance. While the bulk of the public’s attention has been on U.S. domestic mis/disinfo related to QAnon and other 2020 presidential election conspiracies, it got us at the Center for Digital Acceleration (CDA) thinking about our favorite websites, blogs, and resources about mis/disinfo in the Global South or specifically for international development practitioners.
Towards Inclusive Machine Translation: A Case for User-Centered Design in Machine Learning
In November 2020, Masakhane, a grassroots natural language process (NLP) community whose “mission is to strengthen and spur NLP in African languages, for Africans, by Africans,” published a paper titled “Participatory Research for Low-resourced Machine Translation: A Case Study in African Languages.” Machine translation refers to the use of software to translate digital and nondigital text and speech from one language into another. Google Translate is one of the more common examples of machine translation. Most of us have experienced issues translating text, especially sentences and phrases, as Google Translate often has difficulty detecting meaning and context. Due to these challenges, it can often give users incorrect word-for-word translations. (In your free time, search for the #GoogleTranslateFail hashtag on Twitter for a whole host of mistranslated content and a good laugh.)
Google Translate, and other mainstream machine translation tools, are also limited in the number of languages they are able to translate. As of today, Google Translate offers support for only 108 of the more than 7,000 languages spoken across the globe. Many of the languages that are not supported are what machine learning researchers consider to be “low-resourced,” a term used to describe languages that have few digital resources available and, more importantly, that are less commonly taught, endangered, or low density. The Masakhane paper outlines an alternative “participatory” approach for low-resourced languages to standard NLP tasks such as crowd-sourced annotation for training data and evaluation benchmarks. To learn more about the basics of NLP, head to our previous blog post on the importance of NLP in development.
Racist Hardware and What to Do About It
In an astonishing letter to the editor published in the December 17, 2020, edition of the New England Journal of Medicine (NEJM), a group of five doctors from the University of Michigan Medical School presented findings from their study on adult inpatients receiving supplemental oxygen at the University’s hospital. They found that the variance between blood oxygen levels measured through a pulse oximeter—an optical device that estimates blood oxygen by analyzing the light absorbed in an extremity, usually a finger—and more rigorous (and invasive) analyses of arterial blood gas differed substantially depending on whether the patient was Black or white. Moreover, Black patients tended to get more optimistic readings from the oximeter. Such inaccuracies could quite possibly lead to worse clinical outcomes and could be particularly detrimental when treating COVID-19 as careful monitoring of patients’ blood oxygen levels can trigger lifesaving medical care.
Against the backdrop of the ongoing global conversation about racism and bias, one might ask whether the pulse oximeters in this study are racist. Can a piece of hardware even be racist?
Looking Ahead: What We’re Thinking About in 2021
As we (happily) say farewell to 2020, we at DAI’s Center for Digital Acceleration (CDA) feel stronger and more optimistic than ever before. If 2020 taught us anything, it is that adaptation is paramount. The events of the last year have changed almost every aspect of how we think, work, and live, and we would be naïve to think that our digital toolkit won’t change right along with us. Therefore, heading into 2021, we have high ambitions to continue to analyze and elevate inclusive, ethical, human-focused digital products and services that can help us rise to the occasion and address some of the deeply complex issues that 2020 unveiled. Below are seven areas we look forward to exploring further throughout the year—so stay tuned and check back often.
Digital@DAI 2020 Year in Review
2020 has been a year like no other. While those of us in the development sector have long anticipated the increased frequency of once-in-a-lifetime events—as our social, environmental, political, and economic systems grow increasingly strained and interconnected—none of us expected these “problems of tomorrow” to arise as quickly, globally, and devastatingly as they did.
Addressing Concurrent Crises with Digital Tools: An ICTforAg Recap
Reflecting back on 2020, it is still difficult for me to comprehend the many challenges the world faced this year and their implications for agriculture and resilience. From the locust outbreak in East Africa, to wildfires and extreme weather events, and of course, the COVID-19 pandemic, this year has made it clear that in a world increasingly shaped by unpredictability, the digital development community can no longer afford to address one specific challenge at a time. This year’s ICTforAg conference invited its speakers and participants to reflect on this reality and discover how digital tools and technologies can help us respond to concurrent—and increasingly frequent—crises worldwide.
A Vision for Smart Connectivity in the Three Seas Region
During the pandemic, we have been struck by one of the few upsides of this new way of working—the ability to bring together experts and thinkers virtually in ways that contribute to a more global conversation. This was the case recently when DAI spoke at the Three Seas Initiative with leaders and experts from across Europe and beyond about the concept of ‘Smart Connectivity.’
Apply Now: Support USAID’s DRG Center in Addressing Electoral Cybersecurity Threats
The increasingly widespread use of technology in the electoral process in countries around the world creates significant cybersecurity risks, ranging from simple hacks to sophisticated exploitation of hardware or software vulnerabilities. Governments, election management bodies (EMBs), candidates, and parties are often ill-equipped to prepare for and respond to cybersecurity attacks and key decision makers may not understand the gravity of the risks.
USAID’s Democracy, Human Rights, and Governance (DRG) Center views electoral processes as pivotal to a country’s stability and aims to strengthen technical knowledge on addressing electoral cybersecurity threats.
Today, Digital Frontiers releases a request for proposals (RFP) to experienced organizations, firms, or individuals to develop and convene expert briefings and presentations for USAID DRG staff on cybersecurity in elections, including risks, threats, and mitigation strategies.
Considerations for a Successful ICT Strategy in Local Context: Lessons from Timor-Leste
Those with access to technology in various parts of the world use it in similar ways. In places as distant as Chile, Vietnam, and Norway, people use e-commerce platforms for buying and selling goods, emailing each other, and e-calendars for business schedules, and social media platforms for sharing news, communicating, and organizing. Despite these crosscutting uses of technology and often the ubiquity of the platforms themselves (Facebook is the world’s most popular social media site, with 2.6 billion monthly active users), the context in which these technologies exist matter greatly for how that technology is governed and understood.
Technology strategies and policies must be tailored to the local context so that a country can successfully promote the use of technology for growth and prosperity while governing its use to protect citizens and national security. This approach aligns closely with the first two Principles for Digital Development, which are 1) Design with the user—using conversation, observation, and co-creation to create a product or initiative that is truly beneficial and appropriate and 2) Understand the existing ecosystem—considering the particular structures and needs that exist in each country, region, and community.
Eliminating Cyber Violence Against Women and Girls
Today is the United Nations’ International Day for the Elimination of Violence Against Women. Like every year on this day–and any other official “Day” that amplifies the inequalities between women and men–I’m heaving a big sigh… because we’re still here. We still require these Days. We continue to need reminding that women are still fighting for equality all over the world.
These thoughts can get me down, but today, I’m pulling up my positive socks. Observing these Days provides an opportunity to celebrate the progress societies have made in closing gender gaps and can galvanise us to acknowledge the work still left to do. If days like today inspire us to take positive action to shape a better world for women and men, then that is all to the good.
Respond Now: USAID Seeks ICT Regulatory Policy Technical Assistance Services in Latin America, the Caribbean, Africa, and the Indo-Pacific
The Digital Frontiers project is issuing an expression of interest (EOI) to support the U.S. Agency for International Development’s (USAID) Promoting American Approaches to ICT Regulatory Policy (ProICT) activity.
Increasing Adoption and Awareness of Fintech Solutions in Mexico: Q&A with Roberto Velez and Lorena Segura
Launched in 2019, the U.K. Foreign, Commonwealth & Development Office’s (FCDO) Prosperity Fund Mexico Financial Services Programme aims to create a more inclusive and competitive financial services sector accessible to all segments of Mexican society and market entrants. Despite challenges due to COVID-19, this project has been able to hit the ground running with Caravana FinTech, an initiative that seeks to increase adoption and awareness of financial technology (FinTech) solutions that benefit micro, small, and medium enterprises (MSMEs). I recently spoke with Roberto Velez, FinTech Adoption and Socialization Lead, and Lorena Segura, FinTech Socialization Leader, about how the programme is supporting MSMEs to expand their reach and encourage the use of FinTech solutions.
Digital Innovator Series: Talking About Life After an Accelerator with Muuve’s Phanith Phan
We recently spoke with Phanith Phan, the CEO of Muuve, an innovative delivery services startup in Cambodia. Muuve was one of the startups involved in the 2019 Smartscale by Seedstars accelerator, co-funded by the U.S. Agency for International Development-funded Development Innovations project and telecommunications company Smart Axiata. This accelerator model was investor-led and focused on connecting scalable tech startups to mentors, investment advisory services, and targeted technical assistance. Muuve is one of Cambodia’s success stories in a growing digital ecosystem—even through the COVID-19 pandemic. The young team also secured investment from Cambodian venture fund, OOCTANE, a few months after finishing the accelerator in 2019. This is an excerpt from that interview.
Strengthening Cyber Resilience as a Cornerstone of Self-Determination
Cybersecurity and cyber resilience are becoming increasingly crucial considerations for countries seeking to assert sovereignty and self-determination. This desire is particularly acute in regions such as Eastern Europe, South Caucasus, and the Western Balkans, all of which face increasingly complex cyberattacks emanating from nefarious individual and nation-state actors. As these countries navigate digitalization and the interconnectedness of their critical infrastructure (CI) operations, including financial networks and government services, they must strengthen their capacity to address vulnerabilities caused by new technological developments and an increasingly hostile international security environment. Domestic leadership, regional cohesion, and international support are pivotal in strengthening cybersecurity capacity, legislative and strategic frameworks, and institutions in these regions.
Top 3 Considerations for eLearning Design
COVID-19 has caused major disruptions for people from all walks of life. It has dramatically changed the nature of activities we used to do in person, especially those aiming to bring people together to learn, exchange knowledge, and strengthen relationships. As we grapple with the uncertainty of how in-person education and training will continue as the pandemic evolves, many types of learning experiences have preemptively moved online, especially those for adults.
At the Center for Digital Acceleration, we see significant opportunities for creative digital collaboration that would have been impossible just a year ago. Electronic learning has emerged as a particularly interesting category for development solutions. Projects with goals that span the thematic spectrum—from strengthening agricultural supply chains to supporting rule of law to stemming climate change—are considering how to implement digital curricula and thinking carefully about what approaches could work best for their myriad stakeholder groups.
Western Nations Seek to Bulk Up Critical Infrastructure, Digitalization, and Cybersecurity in the Western Balkans
The Western Balkans, like many regions across the world, is navigating the disruptive effects of COVID-19 on their economies, while also digitalizing numerous critical sectors. Critical infrastructure (CI) is defined as “the physical and cyber systems and assets that are so vital to [a country] that their incapacity or destruction would have a debilitating impact on physical or economic security or public health or safety.” Recent threats emanating from malicious individual and nation-state actors remind us that cybersecurity considerations are vital to mitigate potentially widespread and devastating effects. In fact, the need to focus on network and system securities is only accelerated with the unique nature of digital challenges brought on by the COVID-19 pandemic in the region.
Digital Innovator Series: The View from Latvia’s Startup Scene with TrueSix’s Julia Gifford
Even though the U.S. Agency for International Development (USAID)’s Journey to Self-Reliance has been covered extensively by the press, think tanks, academia, and implementers since its 2018 launch (more than 390,000 Google search results and counting), not much has been written about the countries that have actually graduated from assistance. Latvia—a small country of two million people wedged between Russia and the Baltic Sea—was one of 11 central, eastern, and southeastern European states to graduate in the 1990s or early 2000s. After $57 million over eight years of USAID support ending in 1999, what’s going on in Latvia now? Specifically, what’s going on in Latvia’s startup scene and in the digital realm? Quite a bit, as it turns out—from throwable microphones and localization and translation management platforms to one of the world’s first COVID-19 contact tracing apps using the Apple/Google application programming interfaces (APIs). I sat down with my friend of 25 years, Julia Gifford, Canadian-Latvian startup advocate and founder of TrueSix—a Latvian content marketing firm that helps brands get noticed in the U.S. market with strategic content, copy, and advertising—to find out more.
How to Protect Digital Privacy and Security During COVID-19 Response
What do cyber attacks, virtual learning platforms, and the spread of misinformation online have in common?
- All have seen substantial spikes over the past four months.
- Each one would be nonexistent without digital technology.
Technology has served as both an advantage and a hindrance during COVID-19 digital response. On one hand, apps like Zoom have allowed people to stay connected with loved ones while safe at home, and many have been able to work remotely without major disruption to their jobs.
Cybersecurity Frontier Insights Findings: User Perceptions of Trust and Privacy on the Internet
Last week we shared that the Center for Digital Acceleration was launching our most recent Cybersecurity Frontier Insights research into user perceptions of trust and privacy in India and Ghana. Here are the findings from that report, which can be downloaded here.
Since the creation of the internet more than 30 years ago, our lives, economies, and societies have changed dramatically and the restrictions of the COVID-19 pandemic have accelerated change even more. As we’ve developed seemingly endless new methods of online communication, commerce, and civic participation, the international development community has become more acutely aware of a growing digital divide: those who are poor, rural, remote, illiterate, female, or living with disabilities in emerging markets risk being excluded from the benefits of digital transformation. Therefore, especially in recent years and months, we’ve seen valiant efforts from governments, private companies, and the development community to bridge digital gaps aiming to enable more people to access and benefit from online services. However, as access and use has increased, so has the number of digital risks, with data breaches, fraud, surveillance, and cybercrime on the rise globally.
How to Use Digital Payments During the COVID-19 Response
The pandemic is affecting the way people interact with money; how much we spend, what we buy, and whether to opt for digital payments. In the United States, the switch to digital has even led to a coin shortage, and the rest of the world is more reliant on cashless options, too.
Research Launch: User Perceptions of Trust and Privacy on the Internet
DAI’s Center for Digital Acceleration cordially invites you to an online event on findings from our latest Cybersecurity Frontier Insights research into user perceptions of trust and privacy in India and Ghana. We’ll be discussing these findings with a diverse panel of distinguished speakers from A4AI, USAID, FCDO, GSMA, and the Ghana Chamber of Telecommunications.
Understanding Data Tracking: Tips, Tricks, and Tools
I don’t think it will ever be possible to overstate the importance of data privacy. I also don’t think it will be possible to overstate the necessity of digital literacy. And unfortunately, I don’t think it will ever be possible to completely protect our online selves from data harvesting or tracking. However, there are measures we can take to keep our data where it belongs. These measures can be taken by anyone using a phone with access to the internet and help keep us from being tracked.
Launch of Two W-GDP WomenConnect Challenges: Apply Now
DAI’s Digital Frontiers project has just launched a call for proposals for two challenges under the White House-led Women’s Global Development and Prosperity (W-GDP) Initiative’s WomenConnect Challenge.
The WomenConnect Challenge was first launched by Advisor Ivanka Trump and U.S. Agency for International Development (USAID) Administrator Mark Green on International Women’s Day in 2018. Since then, USAID awarded nine grantees that are working to address barriers limiting women’s access to technology and to connect nearly 1 million women in 12 countries.
How to Responsibly Invest in Digital Development During COVID-19 Response
The COVID-19 pandemic has shifted the world to increasingly rely on digital technology to survive. Children are using online platforms to learn. People are using digital payment software to send money to their loved ones, and local businesses are entering the digital space to deliver goods and services that are no longer offered in person.
Digital Development in Southern Africa: How SMEs Access Trade Data Amid COVID-19 Pandemic
In May, Erica Behrens of DAI’s Center for Digital Acceleration, and I worked with the UK Foreign, Commonwealth & Development Office (FCDO)-funded Trade Forward Southern Africa project to map the use of digital communications (i.e. social media use, messaging apps, websites, mobile phones) for trade-related information amongst a sample of small and medium enterprises (SMEs) and other trade stakeholders across sectors in Southern Africa.
Management Information Systems at the Humanitarian-Social Protection Nexus, Part 2: Risks and Benefits
In late 2019 and early 2020, DAI and our partner Caribou Digital worked closely with the former U.K. Department for International Development, now the Foreign, Commonwealth & Development Office) to analyse identification and registration systems in protracted and recurrent crises. For those interested in reading more about the research, the report can be found here. and here.
In this blog—the second in the series—we will dig into data protection and the potential consequences of increasing centralisation. Through an assessment of the literature and existing practice, our research team found that implications of fragmented management information systems (MIS) can be grouped into the following thematic areas: political, protection, legal and ethical, commercial, and operational. As there are numerous risks and benefits of increased centralisation of MIS (our previous blog outlined some of the arguments), we cannot possibly provide an exhaustive list here. But in this post, we will give an overview of some of the considerations, including where care needs to be taken before proceeding; where the political economy must be assessed; and where more data needs to be collected.
Deadline Extended: Applications for Digital Trade and e-Commerce Technical Assistance for the African Union Commission
The Digital Frontiers project has extended the deadline for proposals for a Digital Trade and e-Commerce Advisor to support the African Union (AU) Commission under its ProICT program activity (initial announcement here). ProICT is part of the Digital Connectivity and Cybersecurity Partnership and is designed to fund intensive, dedicated policy, and regulatory engagements in the areas of telecommunications, internet, and ICT. This activity will provide technical assistance to the AU Commission’s Department of Trade and Industry on digital trade and e-commerce work.
Out of the Conference Room, into the Field: Hosting a Virtual Site Visit in Zambia
For the U.S. Agency for International Development (USAID), project site visits are essential for country Missions around the world. Site visits are required as part of each Mission’s performance management and provide opportunities for staff to better understand each activity’s unique context and how local communities experience USAID support. This spring, the COVID-19 pandemic brought travel to a halt around the world. USAID project teams hustled to determine what essential activities could be continued safely, and what would have to be put on hold.
It quickly became clear that site visits could no longer take place. So how could projects—especially those in remote areas without reliable internet connectivity—replicate the important experience of visiting a project in the field?
Defining Digital Justice
George Floyd. Breonna Taylor. Ahmaud Arbery. By now you know the story of the people behind these names and have learned about the violence that cut their lives short. You have heard their names cried out in the streets along with demands to dismantle systemic racism and you have witnessed how their untimely deaths launched a global conversation about racism, justice, and the value of black lives. For many, these three names reinvigorated a hunger for social justice and kicked off months of protesting, donating, reading, and conversing through confusion, anger, guilt, hurt, and hope. With this historic and emotional summer drawing to a close, I find myself wondering what will become of the hunger. As the shock and outrage subside, and corporate promises to “do better” ease mounting public pressure, I wonder how best to ensure this drive for social change lasts.
Management Information Systems at the Humanitarian-Social Protection Nexus, Part 1: Interoperability
In late 2019 and early 2020, DAI and our partner Caribou Digital worked closely with the U.K. Department for International Development (now called the U.K. Foreign, Commonwealth, and Development Office) to analyse identification and registration systems in protracted and recurrent crises. The research explored the feasibility of designing humanitarian aid management information systems (MIS) to link with social protection systems and to support a transition, in the long-term, to state social assistance. Whilst the focus was principally on the interoperability of such systems, our legal, digital, and protection brains also pushed us to focus on the risks associated with data collection, sharing, and storage.
Respond Now: USAID Seeks Research Expertise in Responding to Digital Threats
The Digital Frontiers project is issuing an expression of interest (EOI) to support the U.S. Agency for International Development’s (USAID) Democracy, Human Rights, and Governance (DRG) office’s Responding to Digital Threats Activity.
In the 21st century, digital tools increasingly are becoming irreplaceable assets for societies. While digital tools offer an unprecedented opportunity for vulnerable, underserved, and unserved populations to access information and services, they also expose people, organizations, and countries to risks—for instance, the incitement of ethnic cleansing in Myanmar through digital platforms like Facebook, the manipulation of electoral discourse through the spread of disinformation in places like Ukraine, Brazil, and Vietnam, and the reverberating effects of massive ransomware attacks felt in high, middle, and low-income countries alike. These trends pose a threat to rule-of-law, democratic process, and human rights worldwide. In particular, China is exporting to other countries an internet governance model that conflicts with U.S. values of promoting an open, interoperable, free, and secure internet and democratic norms.
Apply Now: Digital Trade and e-Commerce Technical Assistance for the African Union Commission
The Digital Frontiers project is accepting proposals for a Digital Trade and e-Commerce Advisor to support the African Union (AU) Commission under its ProICT program activity. ProICT is part of the Digital Connectivity and Cybersecurity Partnership (DCCP) and is designed to fund intensive, dedicated policy and regulatory engagements in the areas of telecommunications, internet, and ICT. This activity will provide technical assistance to the African Union Commission’s Department of Trade and Industry (DTI) on digital trade and e-commerce work.
Information Liberation, Part 2: Bringing the Private Sector into the Movement
Open-data sharing can offer huge benefits for development. How do we get the private sector to contribute?
In my previous blog—Information Liberation: What is Open Data, and Why Does it Matter?—posted back in April, I wrote about the Open Data Movement, including its origins, advantages, and relevance to international development. The post referenced Microsoft’s announcement of its support for the movement, vowing to use the company’s resources to address the “data divide” that separates those with access to data and the ability to interpret it, from those without.
With data comes power: the power to make better, smarter decisions; to use information to your advantage; to understand trends and predict future ones. No one knows this better than the private sector—experts in collecting, organizing, and interpreting data to improve business decisions and operations.
Digital Innovator Series: Talking E-Commerce in Nepal with Sastodeal
We recently spoke with Amun Thapa, founder and CEO of Sastodeal.com about Nepal’s growing e-commerce sector, the impact of COVID-19, and the company’s inclusive business model. This is an excerpt of that interview.
How the COVID-19 Pandemic is Accentuating the Digital Divide in the United States
For those of us who work in digital development internationally, the pervasiveness of the global digital divide is constantly top of mind. The majority of our work requires us to understand the digital ecosystem in which we are operating to reach different segments of the population in a specific country. At home in the United States, COVID-19 and the push for virtual schooling and telemedicine has laid bare, for many Americans, how significant and challenging the digital divide is within the United States.
Transforming In-Person Learning into Digital Collaboration
COVID-19 pushed people into their homes and brought to light the different options that exist to transform the way we learn from in-person settings to online classrooms. Although online learning is not new, the adoption of these learning platforms by the general population has been slow in comparison to the development of new technology-enabled education solutions.
What Are Algorithms and How Are They Biased?
In the age of Big Tech and social media, the term algorithm gets thrown around a lot to describe the unseen mechanism that determines what people see on social media or the suggestions that they receive on Netflix. But what exactly is an algorithm? And can an algorithm be biased?
Apply Now: Host USAID’s first-ever Digital Development Online Training
Within the U.S. Agency for International Development (USAID) Global Development Lab, the Center for Digital Development (CDD) addresses gaps in digital access and affordability and advances the use of technology and advanced data analysis in development. DAI’s Digital Frontiers project works closely with the CDD team to roll out and implement USAID’s Agency-wide Digital Strategy, which was released in April 2020.
As part of the Digital Strategy, the Digital Skills Initiative is developing training sessions and resources geared towards USAID staff. These resources will support staff to increase their understanding of–and ability to use–digital tools and skills.
Digital Innovator Series: Talking Equitable Access to Healthcare During COVID-19 Pandemic with Vanderbilt Pediatrics
We recently spoke with Shari Barkin, MD, MSHS, William K. Warren Foundation Chair in Medicine; Marian Wright Edelman Professor of Pediatrics; Director, Division of General Pediatrics, Vanderbilt University Medical Center, about how COVID-19 highlights issues around health equity and acts as a forcing mechanism for technology-driven innovation. This is an excerpt from that interview.
Staying Safe Online—Cyber Hygiene Skills Strengthen Resilience for Small Business, Even In Times of Crisis
As COVID-19 drives more people online for work, entertainment, and even connection to friends and family, digital and data security issues are increasingly important across the United States and around the world. However, citizen-focused digital and data security discussions are still in early stages in some countries, especially in Southeast Asia, and my home base, Cambodia. So—who really gets left behind? It is often the citizens and small companies that rely on digital tools, but do not all have strong cyber skills to safely do business online.
Lessons from a School Teacher: 5 Tips for Effective Distance Learning
Since the world was catapulted into a socially distant new reality earlier this year, donor-funded development projects have been forced to re-envision what it means to transfer knowledge, build capacity, and implement training for staff, partners, and beneficiaries. As a result, DAI’s Center for Digital Acceleration has experienced a swell in requests to support the digital transformation of activities previously envisaged for in-person learning.
As we work to scale support to meet this rising demand, who better to consult on the topic than school teachers? Teachers and students around the world were thrown into distance teaching with little notice and wildly varied levels of preparation. This disruption sparked newfound—but long deserved—teacher accolades from parents suddenly playing an intimate role in their child’s daily learning. Surely anyone with the ability to command a 6-year old’s attention from 30 miles away is worthy of our discipleship. So how did they do it and what did they learn? I spoke with elementary, middle, and high school teachers to glean their insights into engaging learners at a distance. While they had much to share on the matter, what I’ve highlighted below are those takeaways most applicable to the field of international development.
What are User Perceptions of Internet Trust and Privacy in India and Ghana?
It’s been a hard couple of years for the internet. Between election interference via social media platforms, disinformation going viral and facilitating genocides, and most recently, the rampant spread of a conspiracy theories that 5G internet broadband caused the COVID-19 pandemic, optimism in the internet’s force for good seems shaky at best.
I was scrolling Twitter recently and saw a tweet that ironically, mournfully noted, “Remember when this was the platform that was going to save democracy?” I do indeed remember. Simpler times, my friends.
Internet platforms such as Google and Facebook have invested immense resources in countering the more nefarious consequences of internet-enabled bad actors, including significant investment in machine-learning capabilities to uproot disinformation and box out cyber criminals before real harm occurs.
These supply-side focused solutions are indeed powerful, scalable tools in the fight against digital harms. However, to date, there has been less effort to develop demand-side solutions at scale, such as meaningful, global digital literacy and regulatory protections for users.
Disinformation and Dating Apps—A Match Made in Heaven (But Swipe Left Though)
Somehow, we have made it to the halfway point of 2020. This year has been wild, to say the least—more than 500,000 people around the world have died due to COVID-19. The murders of George Floyd, Ahmaud Arbery, Breonna Taylor, Riah Milton, Dominique Fells, Oluwatoyin “Toyin” Salau, and quite literally countless other members of the Black community have led to a crisis of conscience and a (sorely needed, long overdue, how-is-this-only-happening-now) reckoning in the United States. In all honesty, I wrote this post about disinformation and dating apps over a month ago. We held it because the light tone wasn’t right for the historical moment we found—and continue to find—ourselves in. I still think it might be too early. However, as my wise friend and colleague Gratiana Fu points out, the topic of disinformation is especially relevant, right now, precisely because disinformation about COVID-19, Black Lives Matter, and many other topics is spreading so quickly. So, with no further ado—enjoy this silly little romp through the world of disinformation on dating apps.
How Technology Can Reflect Human Bias—And Resources to Understand It
With each technological advancement, more decisions in our daily lives are made by algorithms. They increasingly determine what advertisements we see, whether we’re considered for a job, or which books and movies are recommended to us—and how and where law enforcement is deployed in our communities. The ongoing protests to draw attention to, and eradicate, systemic racism in the United States, and in other parts of the world, have made clear something we already knew—humans are biased. Because we are biased, the technology we create is biased, too.
Over the next several months DAI’s Center for Digital Acceleration will explore this topic by trying to answer the following questions (and more) in a new series: How pervasive is algorithmic bias, and which platforms are the worst offenders? (b) How does algorithmic bias work, and how we can tackle it at a technological level? (c) What other responses—policy, digital literacy, and so on—exist to tackle this phenomenon? (d) What are the effects of algorithmic bias on the broader digital development sector?
The Importance of Personal Digital Security
In the current climate of data collection and data harvesting by every website, company, government or official body that has access to your browser traffic, usage history, and location, your data is always at risk and vulnerable. To add to this, nothing is absolutely, unequivocally, 100 percent secure. Even air-gapped computers that have no connection to the internet, as demonstrated with the CIA-infected Iranian centrifuges with Stuxnet are vulnerable.
Did that sound alarmist? Well, it was meant to be. The good thing is there are simple measures that anyone from web and software developers to computer laypersons can take to protect themselves from the inevitable breach of their data. The more aware we are and the more precautions we take to avoid exposing our “IRL”-selves to the ever-present threats, the better our chances are of staying secure.
COVID-19 Data Analysis, Part 6: Insights from Forecasting COVID-19 Transmission Rates In Mexico with Google Mobility Data
This analysis is Part 6 of a series on COVID-19, with a specific focus on Mexico. The analysis will be updated as we receive additional data and the code for all related analysis will be made available shortly.
For the past two months, COVID-19 has made its way beyond the borders of the United States and into other countries of the Americas, namely the second and third largest countries of the region: Brazil and Mexico. While the United States’ daily incidence of deaths slowly declines, Mexico reported its largest daily incidence yet with 1,092 deaths on June 4.
This Week
Dear friends and colleagues: we had a lighthearted blog post ready to go this week, but in light of recent events, we’re sure it can wait. Instead, we’re using this time to pause and reflect about the killing of George Floyd and the years of structural racism and inequities that his story represents, both in the U.S. and across the countries where DAI works. We’re also thinking about cities and communities reeling from a combination of a global pandemic and widespread unrest. In the meantime, take care and stay strong.
Digital Collaboration: Recommendations from a Six-Week Veteran
Over the past few months, I have been reading article after article about how to run a successful virtual workshop, training, event, and so on, all of which provided useful advice. But, as I have run my fair share of virtual meetings these days, and because I am often described as “direct” by my peers and colleagues, I thought I would take a stab at making my own list of to-the-point recommendations.
Castles Made of Sand: Digital Transformation From the Silicon Up
Silicon chips are literally black boxes to most of us. We understand that transistors are somehow etched in tiny patterns on these silicon wafers, and that these patterns make possible the computers, phones, and other electronic devices that run our modern world. Digital solutions are built on a foundation of silicon, and the landscape of silicon chip production is changing in ways that could have far-reaching impact on how that foundation is laid, and by whom.
Digital Innovator Series: Talking Financial Inclusion with MIX
We recently spoke with Nikhil Gehani, Director of Communications at MIX, a global data resource for socially responsible investors and businesses, about inclusive finance and what it means for low-income countries. This is an excerpt of that interview.
Privacy: How COVID-19 Has Sped Up the Debate
As many countries struggle to manage the COVID-19 crisis, governments globally are looking to data-driven technologies to minimize cases or to help facilitate a transition out of lockdown. The technologies being claimed to protect, prevent, and track include symptom tracking apps that help us understand the disease, digital contact tracing apps that alert us to our interaction with the virus, quarantine enforcement apps that monitor people’s compliance (such as those in Hong Kong, Poland, and Kazakhstan; proposed in Russia and Egypt), and immunity certification that identify individuals who have had COVID-19.
In more developed nations such as the United Kingdom and United States, conversations around data privacy are rife. For example, the UK National Health Service (NHS) is negotiating with Google and Apple about the efficacy of its proposed contact-tracing app in light of the two tech giants’ stringent adherence to privacy.
In the face of serious threats, many of us might say we have a reasonable expectation that our government will use technology to track and pre-empt risks. In the same way we might expect protection from terrorist attacks, we may also accept such measures to be employed during a public health crisis like the current pandemic.
But the vital question is: how can we ensure that the deployment of these digital tools are effective and do not set a dangerous precedent of digital surveillance?
COVID-19 Data Analysis, Part 5: Different Models of Infection Rates in Mexico and What they Tell Us
The challenges of measuring the infection rates of COVID-19 are enormous for even the most prepared countries, given the need for testing to reach a significant enough amount of the population to accurately detect its spread. While the total number of recorded cases in the world thus far have mostly been in the United States, Europe, and East Asia, many low- and middle-income countries have begun to see increases in reported cases.
In Mexico, the number of cases has slowly risen. Public health experts have urgently suggested that testing needs to be dramatically increased to appropriately track the spread of the COVID-19 pandemic. As the graph below shows, the numbers reported from Worldometer corroborate this testing deficit, as Mexico has one of the lowest rates of testing per 1 million people in the region, even among countries of similar size and income per capita.

5 Ways Entrepreneurship Ecosystems are Using Technology to Adapt to the COVID-19 Crisis
During this unprecedented global economic downturn caused by COVID-19, accelerators, incubators, and other entrepreneurship support organizations have a valuable role to play in helping entrepreneurs and small and medium-sized enterprises (SMEs) in emerging and frontier markets. Over the past two months supporting the Shell LiveWIRE global entrepreneurship program and the Kosmos Innovation Center, DAI’s Sustainable Business Group has worked closely with the Global Accelerator Network (GAN) and the Aspen Network of Development Entrepreneurs (ANDE) to leverage technology in support of global entrepreneurship in emerging economies. For corporates, foundations, donors, and development banks that support similar entrepreneurship ecosystems, we offer some learning here from our projects and global networks.

Photo by Oscar Nilsson on Unsplash.
COVID-19 Data Analysis, Part 4: Forecasting Hospital Capacity in Mexico
This post was written by DAI Data Scientist Jamie Parr, with contributions from Greg Maly, Gratiana Fu, Eduardo González-Pier, Susan Scribner, and Kirsten Weeks. This analysis is Part 4 of a series on known risk factors associated with COVID-19, with a specific focus on Mexico. It is the first of several posts that will provide an analytical overview of different aspects of COVID-19 in Mexico. The analysis will be updated as we receive additional data and the code for all related analysis will be made available shortly.
Information Liberation: What is Open Data, and Why Does it Matter?
Less than two weeks ago, on April 21, 2020, Microsoft announced its support for the growing open data movement through the launch of an “Open Data Campaign.” Having recently spent several days researching successful open data initiatives, the statement caught my attention. The World Bank uses the Open Knowledge Foundation’s definition for open data. According to it, open data means data “can be freely used, modified, and shared by anyone for any purpose.” In practical terms, this means data that is both legally open, publicly accessible or with minimal restrictions, and technically open, published in electronic formats that are computer readable and nonproprietary. This type of data is not to be confused with “big data.” As I recently learned, there are differences. For instance, open data derives its value from the sharing of the data and its widespread availability, rather than the volume (as big data does). I won’t be spending more time on this particular topic, but if you’re interested in learning more, I highly recommend reading a guest post we published on the subject in 2016.
Everything Old is New Again: Remembering the Lessons of Early ICT4D in the COVID-19 Era
Often in the early days of digital development, it felt like there was a small group of big, innovative brains in one room all working on similar visions of how best to leverage the growing presence of the iconic Nokia 3310 across the developing world. Frontline SMS, Ushahidi, and other groups were leading the charge from various corners of the earth, and design luminaries such as Jan Chipchase were interviewed in New York Times think pieces on how cellphones could end global poverty. When I moved to Palestine to work for a mobile services company at the end of 2010, I was often in the same room as ICT4D “godparents” Ken Banks, Adele Waugaman, and Erik Hersman, pleading our case to skeptical mobile network operators and Silicon Valley types who found our little ventures thrilling in a slightly Orientalist way. With texting as the tech du jour, everyone codified similar lessons in real time around the successful design of, for example, mobile awareness campaigns. The ICT4D sector grew rapidly across markets, simultaneously building strong use cases for users and development practitioners alike. I do have some hilarious stories of mobile campaign lessons learned from the Somali piracy crisis, but I will save those for another post.
Now, all these lessons are relevant again as we globally try to tackle the COVID-19 pandemic.
New RFA Calls for Innovative Solutions to Advance Digital Skills for Small Firms
Everyone is talking about digital transformation—especially now that digital processes and tools are a mandatory part of daily activities for most businesses, schools, and citizens across the world in response to the global COVID-19 outbreak. The U.S. Agency for International Development (USAID) and DAI have been working to enhance digital skills, improve connectivity, and enable locally led innovation for years. Today, we are all confronted with a new set of urgent challenges. How do we ensure that citizens can safely and effectively use digital technologies to advance their own economic livelihoods and those of their countries?
COVID-19 Data Analysis, Part 3: Rethinking the Global Health Security Index
The next installment in our COVID-19 analysis series connects the dots between the datasets we have explored in our previous posts and brings in a new dataset that came to our attention over the past couple of weeks. In this paper, we look at the relationship between country scores from the Nuclear Threat Initiative (NTI)’s Global Health Security Index and levels of response by country governments measured using the Oxford COVID-19 Government Response Tracker. You can read more about our initial exploratory analysis of the Global Health Security Index here in our previous blog post. Oxford University has provided an initial report of its data on its website.
Approaching Digital Behavior Change Communications in the COVID-19 Era
While tackling the spread of the COVID-19 disease takes a multi-faceted approach, behavior change—especially around personal and respiratory hygiene, proper handwashing, social distancing, and so on—remains a critical need across countries where DAI and our clients operate. Further, as organizations and individuals increasingly embrace digital-based approaches to collaboration, communication, and information gathering, we are presented with an opportunity to incorporate these technologies across behavior change communication strategies. However, as many organizations have experienced since the start of near-global lockdowns, this transition to an all-digital way of working comes with unique roadblocks.
Over the last few weeks, the DAI Center for Digital Acceleration has been exploring how digital communication tools can be used to build communications campaigns aimed at stemming the COVID-19 tide and spreading accurate information about targeted behaviors. We’ve pulled together some quick thoughts on the topic, but frankly, these are principles that apply in most any effort of this sort.
Promoting Resilient Ecosystems: How Cambodians are Adapting in the Face of COVID-19
Five years in Cambodia leading the U.S. Agency for International Development (USAID)-funded Development Innovations project taught me a lot about innovation. I saw innovators employ entrepreneurial thinking to develop out-of-the-box, creative solutions to problems, helping hundreds of thousands of Cambodians—automated phone calls warning people of coming floods comes to mind, as does a mobile test prep application to help high school students prepare for national exams. It’s this entrepreneurial thinking that the world desperately needs in this time of hardship, where livelihoods, the economy, and social cohesion are being challenged in unprecedented ways. Which naturally begs the question: In the face of COVID-19, what happens next in Cambodia’s innovation community?
COVID-19 Data Analysis, Part 2: Health Capacity and Preparedness
- This analysis is Part 2 of a series on known risk factors associated with COVID-19. We aim to use publicly available data sets to identify national and subnational populations most at risk for infection and case fatality. The analysis will be updated as we receive additional data.*
Plan C: How Makerspaces are Providing a Stopgap for COVID-19 Supply Shortages
One of the participants in the Think Global Make Local product development workshop, sponsored by our Cambodia Development Innovations project in 2016, created a design for a toy called Doy Doy. With Doy Doy’s silicone straws and plastic connectors, kids can build complex structures. The product has gone on to achieve modest commercial success locally. I found Doy Doy instructive because of the way its creator, Em Chanrithykol, ended up manufacturing the toy’s plastic connectors. Because of a lack of local injection-molding capacity and administrative barriers to importing parts made by contract manufacturers outside of Cambodia, Chanrithykol turned to a less traditional method: He contracted a local firm to churn out the parts on a battery of 3D printers.
3D printing is slow, expensive, and inefficient. It is great for small runs of one-off items or prototypes, but it is a terrible way to mass manufacture a product. But the lesson of Doy Doy is that a bad way to mass manufacture a product can still be better than having no way to mass manufacture a product. This is why I am currently manufacturing personal protective face shields for Baltimore-area hospitals in my basement.
The Importance of Understanding Digital Divides During the COVID-19 Response
Our work at DAI’s Center for Digital Acceleration intersects with global COVID-19 responses in many ways. Earlier this week, our data scientists presented an analysis of risk factors and last week we got a glimpse at the hardware community’s approach to the crisis. There is another element to our work that I think is critical to highlight—digital ecosystem assessments.
COVID-19 Data Analysis, Part 1: Demography, Behavior, and Environment
This article was written by DAI’s Gratiana Fu, with contributions from Greg Maly, and Jamie Parr. This analysis is Part 1 of a series on known risk factors associated with COVID-19. We aim to use publicly available data sets to identify national and subnational populations most at risk for infection and case fatality. The analysis will be updated as we receive additional data.
COVID-19: Looking for Helpers in the Hardware Community
As the COVID-19 pandemic makes its way across the globe, and even well-resourced health systems struggle with the availability of critical supplies needed to treat patients, initiatives have emerged in the hardware community looking to help solve the shortage of physical supplies.
Unlocking the Value of Digital Transformation in the Social Sector
For many years, the support of international donors to civil society organizations and private and public sectors in the technology field revolved around the provision of equipment, hardware, and software. On many occasions, these types of support have proved ineffective. As researchers wrote in 2013, these investments quickly became obsolete or abandoned. Since then, we in the digital development community have supported international donors and international programming to better integrate technology into our work.
Closing the Gender Digital Divide: What We’re Doing to Bring Women Online
Digital technologies are revolutionizing the way we access information, financing, and networks—all critical tools for fully participating in the global economy. Yet, these technologies, most notably internet connectivity and mobile phones, are not reaching all people equally. In recognition of International Women’s Day, we are looking at one of the most pressing barriers women face to their economic advancement—the gender digital divide—and how DAI is addressing this problem through the U.S. Agency for International Development’s W-GDP WomenConnect Challenge, implemented by DAI’s Digital Frontiers project. (For the latest information, please read our most recent newsletter).
What are Cyber Harms and Why Are They Important for Digital Development?
Since 2014, the digital landscape has significantly changed globally. First, and most obvious, the number of internet users has nearly doubled from 2.8 billion to more than 4 billion in the last six years. Second, and perhaps a bit less obvious, the number of cyber incidents, such as data breaches or cybercrimes, impacting the average internet user, has grown exponentially. For a while now, I’ve been thinking about what these cybersecurity trends mean for our work in digital development. I recently read an article that helped frame the challenge in a way that is easily digestible, even by the least digitally focused development expert.
What's the Best Architecture for a Management Information System?
What is the best architecture for a management information system? I hate to say it, but it depends. Generally though, I do have an opinion, and while your mileage may vary, I think one model might often better serve more use cases.
At first glance, you might think our products team only builds full-stack web applications. That is only half our story. We also spend a significant time providing technical advice to DAI project staff and their government counterparts on the technology solutions they are looking to procure. I call this translating: taking the needs and requirements of the project and explaining it in technical terms to developers and IT experts. One common area we help project staff understand, update, or integrate is a management information system (MIS) in disparate and un-harmonized contexts.
What the Food Systems Dashboard Taught Me About Data for Decision Making
Since I began working with DAI’s Center for Digital Acceleration, I have had the chance to explore many of the exciting opportunities presented by our quickly digitizing world. Though I spend most of my time researching how digital tools and service platforms impact economic empowerment and productivity in the agriculture sector, an area that I am eager to explore further is the role of data in policy and decision making.
Digital Development in the Western Balkans: Kosovo
Last month, the talented, globe-trotting Chloe Carrington posted the first blog on DAI’s activities in Bosnia and Herzegovina in our six-part series about digital development in the Western Balkans. If you haven’t read it, you should. If you did, you’ll know that the United Kingdom’s Foreign Commonwealth Office (FCO) funded DAI to map digital ecosystems across the Western Balkans, with a focus on identifying areas where the FCO can support the technology sector in closing the digital skill supply-demand gap.
Bosnia and Herzegovina, check. Next up—Kosovo!
6 Ways Innovation and Entrepreneurship Promote Prosperity
It is not a coincidence that the most developed nations are also the ones with the highest levels of entrepreneurial activity and innovation. While starting from a minimal level of development helps the latter two, for example, through basic access to capital and institutional stability, the impact of innovation and entrepreneurship on the economy and society more broadly cannot be overstated. In fact, the impact goes beyond usual suspects such as increased productivity, competitiveness, and job creation, and spills over into areas as diverse as regulation, infrastructure, the environment, and social inclusion. Below I provide a (certainly nonexhaustive) list of six such effects. While every issue deserves an article (or even a book!) of its own, these are brief overviews of each point.
Five Trends in Hardware to Watch
With the fast pace of technological change, it can be difficult for development practitioners to keep up with tomorrow’s opportunities and risks. Even for more technologically sophisticated members of the community, the focus on technology often overlooks hardware and exclusively focuses on software. As we begin 2020, I wanted to share the five trends in hardware that I think international development stakeholders—implementers, policymakers, civil society, the private sector, and others—should be watching for changes in the near term.
How the Digital Marketplace is Changing the Way We Eat
It’s the new year and you know what that means…New Year’s resolutions! If you’ve ever uttered the words “New year, new me,” you are far from alone. In 2019, approximately 60 percent of Americans set resolutions and according to a recent survey, the top three were all related to diet and exercise: eating better, exercising more, and losing weight. Sound familiar?
While self-help gurus and exercise enthusiasts may tell us that a little self-discipline is all it takes to achieve these goals, research in the field of health and nutrition has shown that one’s food environment—the physical, social, economic, cultural, and political factors that impact the accessibility, availability, and adequacy of food within a community—can have a larger impact on our health outcomes than we think.
Digital Development in the Western Balkans: Bosnia and Herzegovina
For the past few months, DAI has been working closely with the United Kingdom’s Foreign Commonwealth Office (FCO) to map digital ecosystems across the Western Balkans, and to identify areas where the FCO can support the technology sector in closing the digital skill supply-demand gap.
Through our research, we found a region that is well-placed to increase its share of the dividends of global digital expansion and interconnectedness. The Western Balkans boasts promising digital ecosystems, which are well on their way to creating significant economic growth opportunities, but that in many cases need investment and support to do so. With each country having its own specific trajectory and different operating environment, we have created a series of blogs, each outlining key findings from the six countries in the region: Bosnia and Herzegovina, Albania, Serbia, Montenegro, Kosovo, and North Macedonia.
First up, beautiful Bosnia and Herzegovina.

Baščaršija square.
Looking Ahead: What We’re Thinking About in 2020
In our last post from 2019, we reviewed our top posts from the past year. The most-read articles covered a myriad of digital development topics—bridging the digital gender divide, visualizing remote sense data, and insights into the digital lives of Kabul’s residents to design an open source transparency and citizen participation app. Over the last few years, we’ve seen a sea change in how digital tools and services impact people’s lives globally. Expect 2020 to be no different.
As we get ready for the new decade, here are some topics we’re thinking about when it comes to digital development.
Digital@DAI Year in Review: Top 10 Posts of 2019
This year, Digital@DAI published more than 60 posts covering everything from trends in entrepreneurship ecosystems to the importance of user education for digital development programming and building on user insights to develop an open-source transparency and citizen participation application for the municipality of Kabul, Afghanistan.
We featured digital experts from organizations such as Massachusetts Institute for Technology (MIT)’s D-Lab and information sciences and technology experts from across DAI and from our partner organizations. In addition, we featured program work we do with clients including the U.S. Agency for International Development (USAID)’s Digital Frontiers program. Key topics of interest this year included artificial intelligence, agriculture, citizen engagement, decision support, cyber and trust, and ICT policy.

Five Resources on Human Rights and Tech
This week marked the 71st anniversary of the Universal Declaration of Human Rights (UNDHR)—a founding document which set out, for the first time, fundamental human rights to be universally protected. Working in international development, most of us are committed to the 30 rights laid out in the UNDHR. As the digital revolution evolves, countries have adopted a myriad of legal frameworks to protect citizens in the digital space. These laws include those focused on privacy and data protection. However, often, these policies are not aligned with the most recent technological advancements.
In the humanitarian and development sectors, we are digitising faster than the legal and ethical frameworks governing this digitisation. Some fear that the technology sector remains virtually a human rights-free zone.
Studying River Health through Citizen Science and Data Analysis in Maryland
Since 1970, DAI has worked in 160 countries on development issues ranging from good governance to environmental problems. But what about scientific policy-oriented initiatives in our backyard? With a headquarters in Bethesda, Maryland, DAI is surrounded by a vibrant and diverse social and ecological community, and civil society organizations that focus on sustainable development. At the Center for Digital Acceleration (CDA), we’ve had the good fortune of engaging two such organizations— Spa Creek Conservancy (SCC) and the Environmental Center at Anne Arundel Community College (AACC)—that combine formal academic research with citizen science and use data to bring awareness to the health of the Chesapeake Bay watershed.
Water testing locations and test results in Spa and Back Creek.
Unearthing Lessons by Revisiting—Not Reinventing—the Wheel by Utilizing Data Science
As we enter what the World Economic Forum refers to as the “fourth industrial revolution”—a profound transformation of industries and institutions driven by artificial intelligence, machine learning, robotics, and augmented reality—international development practitioners are shifting toward data-centric business practices that require new systems, more efficient work flows, and modern skill sets. While the promise of newly available data is driving a desire to answer new analytical questions, lessons from more than 50 years of development projects lay dormant in Word and PDF documents stored in disparate folders, databases, and online portals by a wide array of stakeholders.
Apply Now: Artificial Intelligence and Machine Learning in International Development
Artificial intelligence (AI) and machine learning (ML) technologies, although still relatively new concepts, are garnering a vast amount of interest in international development across sectors and geographies. The U.S. Agency for International Development (USAID)’s Center for Digital Development (CDD)’s Strategy & Research (S&R) team published a report in 2018, “Reflecting the Past, Shaping the Future: Making AI work for International Development”, based on extensive research on this rapidly growing field.
USAID would like to translate the report’s recommendations into an actionable format so the lessons and good practices are accessible to USAID program staff and implementing partners that may have limited familiarity with, nor time, to devote to the topic.
Lessons Learned from Development Innovations Team: Adapt, Serve Users, and Tell Your Story
As an avid and committed reader of Digital@DAI, you have no doubt come across our extensive coverage of the Cambodia Development Innovations (DI) project, funded by the U.S. Agency for International Development (USAID). My colleagues have chronicled efforts to address flooding by building hardware with locally available parts, the project’s design research with civil society groups in Phnom Penh, and everything in between. With a mandate to strengthen Cambodia’s civic tech ecosystem and facilitate connections between civil society and the local tech community, DI was one of the only USAID projects that focused on technology and innovation ecosystems. But alas, all good things must come to an end—especially when the mission has been achieved and staff have worked themselves out of a job.
Part I: Big Data in Agriculture Conference Download: Building Trust and Fueling Innovation
As a data enthusiast with a budding curiosity in digital agriculture, I was excited to attend the recent 2019 CGIAR Big Data in Agriculture Convention in Hyderabad, India. The event brought together attendees from around the globe to connect over the theme of Trust: humans, machines, and ecosystems. The CGIAR Big Data Platform aims to “use big data approaches to solve agriculture development problems faster, better, and at greater scale than before.” The platform does this by connecting CGIAR-affiliated researchers from around the globe with development practitioners and ag-tech providers.
Not only did I have the rare opportunity to engage with super smart scientist-types who, unlike me, have job titles like “plant geneticist” and “mycology and plant pathology specialist,” but I also was compelled to consider the definition and role of trust in the application of data and technology to building resilient global food security.
Respond Now: USAID Seeks ICT Regulatory Policy Technical Assistance Services
The Digital Frontiers project is issuing an expression of interest (EOI) to support the U.S. Agency for International Development (USAID)’s Promoting American Approaches to ICT Regulatory Policy (ProICT) activity.
10 Trends Changing Entrepreneurship Ecosystems
If you’re supporting early stage entrepreneurs in emerging and frontier markets, there’s a lot to be excited about as we approach the start of the third decade of this century! Over the past year supporting the Shell LiveWIRE global entrepreneurship program and the Kosmos Innovation Center (KIC), I’ve had the chance to attend some rather dynamic conferences, ‘un’-conferences, meetups, and pitch events with the Global Accelerator Network (GAN), the Aspen Network of Development Entrepreneurs (ANDE), Techstars, and the International Business Innovation Association (InBIA). I’ve observed some trends from the inspiring incubator and accelerator program managers that I’ve gotten to meet from around the world—and will share the best ones below:
Apply Now: Support USAID on the Digital Development Awards and Communications Activities
Within the U.S. Agency for International Development (USAID) Global Development Lab, the Center for Digital Development (CDD) addresses gaps in digital access and affordability and advances the use of technology and advanced data analysis in development. DAI’s Digital Frontiers project works closely with the CDD’s Knowledge and Insights (K&I) team, which leads the Center’s work in knowledge management, communications, and training.
Digital Insights: How the Disability Community in Honduras Uses Digital Tools
Read this post in Spanish.
Studies on how many disabled people live in Honduras are scarce. Results of a survey by the National Statistics Institute (INE), carried out in September 2002, showed there are 177,516 people with disabilities in the country. Academic studies tell a different story. They estimate that the number of people in Honduras with disabilities is closer to 381,287. These differing reports prevent the government, institutions, and civil society from effectively thinking through how ensure that services are accessible to those with disabilities.
Digital Insights: El contexto digital de la población con discapacidad en Honduras
Read this post in English.
Se estima que el número de personas que viven con algún tipo de discapacidad en América Latina y el Caribe entre 2001 y 2013 fue de más de 70 millones (o 12.5 porciento de la población regional total, el 12.6 porciento de la población de América Latina y el 61 porciento de los países del Caribe).
En Honduras los estudios acerca del tema de discapacidad son escasos y limitados. Según los resultados de la Encuesta Permanente de Hogares con Propósitos Múltiples del Instituto Nacional de Estadística (INE) realizada en septiembre 2002, se encontró que en Honduras existían 177,516 personas con discapacidad, lo que representa una prevalencia de 2.65 porciento, con predominio masculino (55 porciento) en comparación de la población femenina (45 porciento). Sin embargo, estudios recientes del [Censo 2013 del INE] indicaron la existencia de 205,423 personas con discapacidad, y otro estudio de Flores, et al. (2014) encontró una tasa de prevalencia del 4.6 porciento, que significa un total de 381,287 personas que viven con discapacidades asumiendo una población de 8.2 millones.
Building Digital Medical Records for Floating Villages in Cambodia
How do you digitize medical records in Cambodia when your clinics are on a lake, have minimal internet connectivity, and are four hours away from the nearest big city? Impossible, you say? Not quite. Let me introduce you to the Lake Clinic (TLC), a health clinic working to solve this complex challenge with the support of the six-year, Development Innovations (DI) project, funded by the U.S. Agency for International Development.
Making Sure Data Science For Good Does Good
Last week at the 74th U.N. General Assembly, the Rockefeller Foundation announced a $100 million Precision Public Health initiative to integrate data analytics and data science tools such as machine learning into the community health systems of low- and middle-income countries. During the announcement, Rockefeller noted the significant impact of data science innovations in the most privileged communities, explaining its hope to replicate this effect to improve healthcare for people globally. The initiative aims to save at least 6 million women and children’s lives by 2030.
Digital Development for Newbies, Part 1: The Basics
I joined DAI’s Center for Digital Acceleration (CDA) several months ago as an international development professional: familiar with ADS 302, Geo Code 937, Form AID 1420-17, among other industry acronyms, but a newcomer to the language of tech trends, digital buzzwords, and product design. I found the CDA team to be both inspiring and daunting, boasting individuals with unique expertise and passions—whether cybersecurity, human-centered design, remote sensing, blockchain, or the Internet of Things. As a neophyte, it’s easy to be overwhelmed by what you don’t know in the seemingly limitless world of digital technology but I’m here to help! If you, too, are new to this sphere, what do you need to know to integrate digital tools into your development programs or proposals? Below are some key points to get you started.
Applying the Principles for Digital Development in a Flourishing Digital Ecosystem
As a co-facilitator at a recent Feed the Future training on digital development for resilience and food security in Nairobi, I was struck by the stark contrast between the short amount of time (a scant four years) I’ve been settling debts with friends on Venmo and the participants’ resounding “we’ve been using it forever” response when I asked how long they had been using Kenya’s mobile payment system, M-Pesa. While I can imagine a world without Venmo, it is clear that, for many Kenyans, life without M-Pesa is inconceivable.
Confidence Not Competence: What Holds Women Back from Embracing Tech in Development
Throughout my life, I’ve heard women grumble about using technology—from my mom, from friends in school, and from work colleagues—yet these are highly educated, often extremely logical thinkers that excel at, well, Excel!
The irony of the situation has been troubling me in the past few months. Why? Because there is a clear contrast in attention paid to the benefits of empowering women and girls through technology in low-and middle-income countries, with the attention paid to empowering women and girls through technology in high-income environments.
Lessons from Cambodia: How to Grow a Girls’ Tech Entrepreneurship Challenge in Six Years
How do you get Cambodian girls engaged in addressing the digital gender divide? This is a question that the six-year Development Innovations (DI) project has been wrestling with since it was launched by the U.S. Agency for International Development—and that DAI’s Center for Digital Acceleration (CDA) and DI have regularly chronicled on their blogs.
Lessons from the Makerspace Community in High-Income Countries
Makerspaces—akin to coworking spaces with tools such as 3D printers and computer numerical control (CNC) mills as well as more traditional woodworking and metalworking items—offer participants access to equipment traditionally the domain of specialists or well-funded firms. Along with the proliferation of independent makerspaces starting in the mid-2000s, national organizations emerged to promote the model and connect regional maker communities, as well as offer a commercial platform for vendors making innovative tools for that market.
Visualizing Remotely Sensed Data: True Color and False Color
What kind of images do you think of when you imagine Google Maps of our planet? Landmarks? Roads? Roads on top of satellite imagery? When we see that satellite imagery base map, we generally expect to see a representation of the earth that matches our reality. This is what we call in the world of remote sensing, “natural color.” For the average person, this use of earth-sensing satellites is the most useful, but in reality it represents only a fraction of the information gathered.
Center for Digital Acceleration Partners with Award-Winning Tech Startup Skilllab
One of the ways DAI tackles global challenges is by partnering with other innovators to invest in promising solutions. In joining forces with tech startups that align with our mission, we bring the power of technology and entrepreneurship to bear on global development challenges.
In 2016, for example, we supported four startups through our ‘Innovation into Action Challenge’, including education tech firm Laboratoria, renewable energy enterprise Solar Sister, and m-health platforms ClickMedix and ThinkMD. Earlier this year, we announced our investment in ClickMedix. We’ve also invested in Ghanaian startups that emerged from the Kosmos Innovation Center. Keeping with this tradition, DAI’s Center for Digital Acceleration is pleased to announce a new strategic partnership with our friends and colleagues at Skilllab.
Navigating Barriers to Digital Inclusion
When I first began learning about digital development, I thought of it as a new frontier that could push international development out of its modus operandi. New digital tools could provide individuals, communities, governments, and organizations with new sources of information at rapid speeds—enabling new means of collaboration to propel development objectives.
Digital technology is unique for two reasons. First, digital is informative—providing users with increased access to new information and opportunities at their fingertips. Second, digital is informed—enabling users to input information that will conceivably be used by industries and governments to tailor and update their products and benefit their business and economies to improve customer experiences.
Understanding Cybersecurity for Healthcare Professionals
We live in exciting times. The ways in which we store and engage with health data have been transformed with the creation and adoption of digital health technology. Whether it’s using a Fitbit, accessing your vaccine records online, or virtually connecting with your doctor, understanding your health status in real time has never been easier… for some of us. We at DAI Global Health are working tirelessly to increase access to healthcare in low- and middle-income countries by leveraging digital health technologies. The goal is to empower patients and professionals providing care to them to use data to make smart decisions.
New USAID Guide: How to Create Digital ID for Inclusive Development
Access the U.S. Agency for International Development (USAID)’s new Guide to Creating Digital ID for Inclusive Development.
Identity is deeply personal. Issues of identity are complex and tied up with power, privacy, and protection. Yet identifying constituents is often critical to organizing and managing global development projects. Decades of development work have relied on ad hoc identity systems to administer programs, yet today we find that nearly 1 billion people still lack representative identification.
USAID’s 2017 report Identity in a Digital Age: Infrastructure for Inclusive Development documented some of the complexities that arise when we create or use digital ID in development programming. Done well, these systems can provide a unique, trusted, multipurpose ID to everyone, which is key to economic and social development.
Cybersecurity Lessons from Ukraine
Read this blog in Ukrainian.
When you walk into a room full of government officials, civil society organizations, and private companies discussing cybersecurity, you expect to hear disagreement. The exact opposite happened during the recent DAI-SocialBoost Cybersecurity Roundtable and Workshop in Kyiv, Ukraine.
The event started with a panel discussion with representatives from a myriad of government institutions working to address Ukraine’s cybersecurity challenges. Representatives came from the Ministry of Energy, the Pension Fund of Ukraine, State Service of Special Communications and Information Protection of Ukraine, the Presidential Administration, Ministry of Infrastructure, and National Information Systems. Joining them were representatives from the company Information Systems Security Partners (ISSP) and the law firm Sayenko Kharenko.
Карти, гроші, VPN: кібербезпекові реалії в Україні
Read this blog in English.
Cупротив та неузгодженість — напевне, той асоціативний ряд, який спадає на думку, коли уявляємо, що в одній кімнаті мають зустрітися державні управлінці, громадський сектор та представники бізнесу для обговорення тонкощів кібербезпеки. Проте, на Cyber Security Day - серії подій, які команда SocialBoost нещодавно організувала з новим партнером DAI, нам вдалося досягти абсолютно іншого ефекту.
Digital Gender Divide: Latifa Yari's Story
Let me introduce you to Latifa Yari, a 24-year-old student who will graduate from the Niger Higher School of Telecommunications (E.S.T.) this year with a degree in computer science. In 2018, Latifa won the Miss Geek Africa* competition with an app called Saro (“security” in Hausa) that connects emergency response services to citizens who have been in accidents. After that win, she founded the startup InnovElle, to develop digital social solutions and coach girls and women in digital technology. Latifa’s accomplishments are impressive and in the context of Niger, where there is a large digital gender divide, they are astounding. This is why during a recent trip to Niger I reached out to Latifa (thanks, LinkedIn!) to learn her story.
Facebook’s Libra Currency: A Digital Development Perspective
When Facebook announced its first foray into the digital financial space with its new digital currency Libra last month, the digital development community collectively sighed and Twitter lit up with both praise and concern. While it’s easy to get out the pitchforks for something like this—and in many ways rational, given how Facebook was manipulated to exacerbate the Rohingya crisis, used by Cambridge Analytica, and part of a myriad of other breaches of trust in which Facebook has proven itself a questionable steward of its self-built digital nation—I’m not going to take a side on whether Libra is good or bad. Rather, in this blog, I will lay out some key questions and considerations that need to be fully addressed.
Mobile Technologies Push Latin America Forward
Esta entrada también está disponible en Español.
The digital ecosystem in Latin America is pushing countries to accelerate public-private collaboration on digital transformation.
At the recent GSMA Mobile 360 LATAM conference, we heard a lot about how 5G networks will bring about a technological, economic, and social revolution around the world. Many speakers—including GSMA CEO Mats Granryd—urged authorities and industry representatives to work jointly to accelerate the adoption of 5G networks in the region so that Latin America is not left behind.
Las Tecnologías Móviles Empujan a América Latina Hacia Adelante
This blog is also available in English.
El ecosistema digital en la región de América Latina está presionando a los países para acelerar la colaboración público-privada en la transformación digital.
En la conferencia Mobile 360 LATAM de GSMA, escuchamos constantemente cómo se espera que las redes 5G traigan una revolución tecnológica, económica y social en todo el mundo. La pregunta fue planteada por muchos oradores, entre ellos Mat Granryd, CEO de GSMA, quien instó a las autoridades y la industria a trabajar conjuntamente para acelerar la adopción de redes 5G en la región para que América Latina no se quede atrás.
Open Source Versus Proprietary Data Management Stack—Which One is Best for Your Team?
As a product development team, we spend a lot of time listening to the needs of users, particularly when it comes to their desire to collect and analyze data. And while projects have unique needs, they often ask for a common set of technology solutions. These include the ability to:
-
Digitally collect and manage data - offline or online as mobile bandwidth permits.
-
Learn as much as they can from their data, often through a series a dashboards or reports.
-
Upload products and share learnings with a public audience.
-
Maintain an internal system for data sharing, so that people only have access to certain information.
Most importantly, these tools should be easy to use, and ideally not too expensive to build or maintain.
All of these are reasonable requests. If prioritized, organizations should be able to develop and maintain highly functional data management and analysis solutions. So why do so many organizations struggle to maintain these kinds of systems? In this article, I’d like to outline two very different routes that organizations can take when trying to build out their systems: 1) completely proprietary solutions v. 2) open source technologies.
Power Beyond the Prize
The Bill & Melinda Gates Foundation recently hosted a convening between two sets of challenge prize winners: Feed the Future’s, through the U.S. Agency for International Development (USAID), Fall Armyworm Tech Prize finalists and the Grand Challenges Explorations (GCE)’s Tools and Technologies for Broad-Scale Pest and Disease Surveillance of Crop Plants in Low-Income Countries winners. The objective was to catalyze collaboration between the two groups of innovators working in digital agriculture, engineering, modeling, remote sensing, pathology, and chemistry for the benefit of farmers.
Digital Identity Series Part 3: Barriers to Inclusion for All
 Any ID—whether state-issued or purpose-made for services such as cash transfers—in some way reflects levels of equality, whether these are inherent in the technology or prevalent in the social ecosystem. For instance, research from the GSM Association (GSMA) in Bangladesh, Nigeria, and Rwanda showed that citizens feel that equality in national ID is important as it reflects equality in citizenship status for men and women. If a biometric-based ID card is created in a refugee camp to facilitate cash transfers, every person living in that camp can rightfully expect to be registered regardless of age, gender, or ethnicity.
Any ID—whether state-issued or purpose-made for services such as cash transfers—in some way reflects levels of equality, whether these are inherent in the technology or prevalent in the social ecosystem. For instance, research from the GSM Association (GSMA) in Bangladesh, Nigeria, and Rwanda showed that citizens feel that equality in national ID is important as it reflects equality in citizenship status for men and women. If a biometric-based ID card is created in a refugee camp to facilitate cash transfers, every person living in that camp can rightfully expect to be registered regardless of age, gender, or ethnicity.
We list a number of ways in which bias can manifest in digital identities to kick off some discussion and move toward solutions. While reading this, I encourage you to think how we can make sure digital ID systems are inclusive.
Changes in Open-Data Policy in Global Development are a Game Changer
You saw it coming. You’ve been collecting geospatial data on your projects for years. Maybe uploading it to a faraway server or sharing it with local partners…or stashing it away on your laptop or external hard drive. But no one else was ever able to use it. And you were sort of irritated that you had to ask a million people for the same data every time you started a new development project in a different country.
Building the Future of Tech-Enabled Agriculture
Since 2016, Digital@DAI has kept its readers updated on the latest from the Kosmos Innovation Center (KIC) in Ghana, from young entrepreneurs’ agritech product concepts to international awards it has received. In the three years since the KIC’s launch, funders of all sorts—from bilateral donors to corporate social investors—have embraced the potential of Africa’s growing startup ecosystem to support socio-economic development and create new solutions to some of the continent’s most persistent challenges. In that time, KIC and DAI have learned a lot about what it means to support youth-led technology entrepreneurship.
We’ve compiled our findings in the latest CDA Insights paper titled, ‘Building the Future of Tech-Enabled Agriculture.’ In addition to providing lessons for both funders and implementers in this sector, we created profiles of select KIC entrepreneurs and captured their journeys.
El desarrollo de Coffee Cloud: Una herramienta de precisión utilizada por agricultores en la región centroamericana
This post is also available in English.
Durante más de un siglo, la roya ha representado una seria amenaza para la industria cafetalera mundial, especialmente en la era del cambio climático. No obstante, la toma de acciones eficaces y de forma coordinada entre los países centroamericanos productores de café ha sido una tarea difícil de lograr. En consecuencia, esta enfermedad ha continuado propagándose y sus efectos han sido devastadores. Entre 2012 y 2013, la roya ocasionó que la región centroamericana experimentara una reducción del 15 por ciento de su producción de café, lo que incluyó un alarmante 31 por ciento en Honduras. El gráfico siguiente muestra las pérdidas que experimentó cada país durante este período.
Building Coffee Cloud: A Precision Ag Tool Used by Farmers Across Central America
Esta entrada también está disponible en español.
Coffee rust has menaced the global coffee industry for more than a century, but particularly in the era of climate change. Nevertheless, effective, coordinated action between coffee producing countries across Central America has remained elusive, and as a result the disease has spread—to devastating effect. In 2012 and 2013, coffee rust reduced the region’s coffee production by 15 percent, including a staggering 31 percent in Honduras. The figure below shows the losses each country suffered during that season.
You Keep Using That Word: Why “Scale” Doesn’t Mean What You Think It Means
The Merriam-Webster Dictionary offers seven definitions of “scale,” involving variously weight, fish, climbing, maps, music, and—unexpectedly—lumber. Notably, none of these meanings is a synonym for “to embiggen,” the usage favored in the tech and development worlds. In these environments, which share little else, taking something “to scale” always seems to evoke Carl Sagan-esque notions of quantity. What this reductionist approach to vocabulary loses (in addition to small stiff plates that cover much of the body of some animals) is the range that makes this word truly useful. In English, if not in Silicon Valley, you can scale up, but you can also scale down.
Access for All in a Digital Economy: A Reflection on DAI Development Matters Roundtables in Nigeria
The technology revolution in Nigeria is remarkable compared to other countries in Africa (the country completely skipped the landline stage of development!). As one of the top destinations for investment in Africa, Nigeria is home to booming tech startups that provide a collaborative environment for entrepreneurs across sectors. Powered by the Nigerian government’s commitment to digital access, the digital ecosystem in Nigeria is likely to evolve further. Within this context, DAI’s office in Nigeria recently hosted two roundtables—one in Lagos and one in Abuja, both featuring insights from DAI’s Vice President of Technical Services, Brigit Helms, who recently published “Access for All: Building Inclusive Economic Systems.”
Apply Now to the Women’s Global Development and Prosperity Initiative WomenConnect Challenge
Digital technology has revolutionized the world by providing instant access to information, finance, and networks—all of which are necessary for women to reach their full economic potential and create more self-reliant communities.
Today, 1.7 billion women in low- and middle-income countries still do not own mobile phones. The internet user gender gap is greater than 40 percent in some countries. The persistent gender digital divide is reinforcing—and even exacerbating—existing socioeconomic gaps between men and women.
Advancing women’s digital connectivity is key to promoting their empowerment in an increasingly digital world.
10 Tips to Work Better with Small ICT4D Firms
Hi, Digital@DAI readers! My name is Inta, and I am the newest staff member at DAI’s Center for Digital Acceleration. I come to DAI from GeoPoll, a U.S. registered small business in the mobile for development space. Making the transition from a small business specializing in ICT4D to a large business with a rockstar ICT4D team has given me some unique insights on the needs of small businesses. It has also provided me a big platform (thank you, Digital@DAI!) to share them with others, particularly people working for other major players in the international development sector. Below are some tips for using smaller, specialized technology firms—particularly U.S.-registered small businesses—more effectively in your development projects:
Longing for my SuperApp: Where’s the American Go-Jek?
Earlier this year I underwent a major life transition. After over four years living in Southeast Asia while supporting DAI’s ASEAN-U.S. PROGRESS project, I packed up my Jakarta apartment, shipped my belongings, and said farewell to the people and place that had become my home. The year 2019 was certain to be one of adjustment and inescapable reverse culture shock as I transitioned to life in America and a new position at DAI’s Bethesda, Maryland, office.
5 Takeaways From ICT4D 2019
This year’s ICT4D Conference took place alongside Lake Victoria in gorgeous Kampala, Uganda. It was my first time attending, and it was great to catch up with friends and colleagues (old and new) and marvel at how much bigger the ICT4D sector is since I first joined it in late 2010 and Ken Banks and I had been invited to speak on the one mobile for social good panel (true story!) at a telecoms event.
GIS Toolkit Overview Part I: Remote Sensing
Geographic information systems (GIS) are often misunderstood, or unknown to many. Even in the development community, we often have a shallow understanding of the technology once we delve into methodologies or use cases—particularly with satellite imagery, or more aptly, remotely sensed data. GIS and remote sensing are not synonymous, but scientifically and inextricably linked. When choosing a GIS/remote sensing methodology or technical analysis component for a project, it is important to understand the strengths and shortcomings of the available tools.
GIS image developed by the author when he was working for the Amazon Conservation Association.
Designing A Wildlife Identification Tool in the Philippines
Human-centered design (HCD)—the design and management framework pioneered by greats like IDEO.org and taught in countless design and business schools—is taking the development world by storm. And rightly so, in our opinion. HCD’s focus on empathy and creativity helps us design better, more sustainable solutions to some of the most difficult development challenges. We won’t go into too much detail on the broader HCD process or its application in digital development; my colleagues have written extensively on the excellent design work they’ve facilitated in places like Cambodia, Nepal, and Guatemala. What we’d like to do today, rather, is tell you about the time we almost perished while shadowing rangers in the forests of the Philippines, and what we learned in the process.
It is possible there is a bit of hyperbole inserted here. Possibly.
Apply Now to Redesign the USAID Center for Digital Development’s mAccess Online Platform
A digital ecosystem is the how and why users interact with government services, digital financial tools, and each other using mobile devices. A single data point alone may not tell the whole story for digital inclusion and how to best reach those in low-connectivity settings globally. To help address this challenge, the U.S. Agency for International Development (USAID)’s Center for Digital Development (CDD) developed the mAccess diagnostic site, an online tool for global decision makers to analyze the availability, cost of connectivity, and number of users for more than 100 countries. The mAccess tool was launched in early 2016 and has been shared across USAID.
Digital Identity Series Part 2: Digital Identity and Politics
 Welcome back to the Digital Identity series. This week we continue the discussion of digital identity, with a focus on the politics of digital identification.
Welcome back to the Digital Identity series. This week we continue the discussion of digital identity, with a focus on the politics of digital identification.
Let’s start with the recognition that a formal identity is often a starting point for inclusion—without it, a person may not be able to access services such as health care, banking, or education. In humanitarian emergencies, a digital identity may be required to receive vital provisions such as food, water, and medicine.
What Makes This Wireless Technology (5G) Different From All Other Wireless Technologies?
When thinking about the internet in an ideal world, I often think of an independent platform that provides a mechanism for free expression, commerce, and the exchange of ideas. Yet, as more and more of the global population comes online, the internet has become a reflection of global dynamics and geopolitical undercurrents. Today, this reality is manifesting itself around the impending roll out of 5G.
5 Tips for Doing International Design Research
DAI’s Center for Digital Acceleration (CDA) relies heavily on ethnographic design research in our work. By focusing our efforts on people and the institutions around them, we:
- Define the problem in their terms, not ours;
- Learn of, and about, previous attempts to solve the problem;
- Develop our understanding of local culture and history, as well as how people seek and share information and use mobile technology so we can meet them where they are;
- Mitigate the risks inherent to spending limited resources developing software or building digital tools, given the costs of doing so;
- Build ownership of the solution among the population; and…
- Enlist those who participate as promoters of the solution among their personal and professional networks.

The author teaching design research in Phnom Penh with the USAID Cambodia Development Innovations project.
From One Qualie to Another: Insights from Qual360 2019
I have a confession to make: I am a bonafide, card-carrying qualie. For those of you who aren’t familiar with this term, it’s a (nerdy) colloquialism to define people who are really into qualitative research. I swear, it’s a thing.
So yes, I am a qualie. I have been involved in conducting qualitative, ethnographic research in some way or another throughout the course of my sinuous career. I get jazzed by learning about people’s lived experiences—the barriers they encounter when attempting to improve their health and well being; the things that make changing behavior a snap; all of it. Throw some neuroscience in there to understand what’s happening in the brain and the ways in which emotional responses catalyze behavior change? Yes. Yes, please. I am in heaven.
Game Mechanics—Great Tool for Designing Digital Development Services
📱 Smartphone connections continue to rise and people, globally, love to game. The Global Systems for Mobile Communications Association (GSMA) estimates that by 2025 78 percent of all developing market mobile connections will be smart. By that time GSMA predicts that India will be the second-largest smartphone market by adoption globally (ahead of the United States), with 1 billion smartphone connections. Interestingly, India is already among the top five mobile gaming countries globally, expected to surge to 368 million gamers in 2022. If this is a bellwether for developing markets, we can expect gaming to be a significant force across the global south.
Digital Identity Series Part 1: Digital Identity and Informed Consent
This post marks the launch of a Digital Identity series here on Digital@DAI. It is a pivotal topic to many of our technical areas: from health service provision, to cash transfers, and voter registration. It is also a topic garnering increased attention with the debate over privacy and data security—and the global refugee crisis reinforcing the opinion that there is “no single factor that affects a person’s ability to share in the gains of global development as much as having an official identity.”
Over the next few months, we will look at some of the issues and opportunities around Digital ID in the development space. Today, we look at informed consent: what it means to the development sector, the difficulty of getting it, and what we can do to make sure we aren’t leaving people behind, while respecting their privacy and the security of their data.
Nobody Cares What Tech You Use
Technologists and developers love to talk about the best tools for building new technology. MERN or MEAN stack, functional vs. object-oriented programming, vanilla development or frameworks. The internet is ripe with these discussions and attend any tech meetup and you’ll easily find multiple discussions comparing one tool to another. The performance and usability of one over the other, as if that is the goal.
Is Your Data in a Lake or Water Treatment Plant?
They say to write about what you know. For the first part of my career and through my formal education, my work was all based in the world of water and sanitation. Glamorous stuff—pipes and pumps, fecal coli-forms and treatment options, toilets and activated sludge. It made for great dinner conversation (or so says my wife). At some point, I made the transition from a water guy who worked with a lot of data to a data scientist who knows about water. And as I dive deeper into the analogies and lingo of modern data systems and tools, I lean on my engineering training to make sense of it all.
Apply Now to Support Digital Tools and Approaches for USAID’s Bureau for Food Security
Rapidly changing access to digital tools such as basic mobile phones is changing the landscape for how we can address the challenges to ending global hunger, undernutrition, and extreme poverty. “Despite our collective progress in global food security and nutrition over recent years, a projected 702 million people still live in extreme poverty; nearly 800 million people around the world are chronically undernourished; and 159 million children under five are stunted. Food security is not just an economic and humanitarian issue; it is also a matter of security, as growing concentrations of poverty and hunger leave countries and communities vulnerable to increased instability, conflict, and violence.” (U.S. Government Global Food Security Strategy 2017-2021).
KIC Mauritania: Winners Announced!
Since 2016, DAI has provided support to the Kosmos Innovation Center (KIC), which got its start in Ghana and expanded its work Mauritania in 2018. Last week, KIC Mauritania’s 2018 cohort of young entrepreneurs pitched concepts to a panel of judges, competing for more than $85,000 in total seed funding. Unlike KIC Ghana, which focuses solely on support to agritech startups, KIC’s Mauritanian startups have built a wide range of solutions across various sectors, from waste recycling to healthcare. Here’s an overview of this year’s finalists, their business concepts, and the final winners of the competition.
Building a Culture of Innovation in Cambodia
Many in international development want to be “innovative,” but how do workplaces develop cultures that promote useful innovation? The U.S. Agency for International Development (USAID) launched Development Innovations (DI) in 2013 to help Cambodian civil society organizations and tech companies leverage technology to address social needs. This objective would require new ways of thinking to create new ways for solving problems.
Machine Learning Changes the Business Case for Automated Phishing Attacks
Researchers have demonstrated the capability of machine learning to help with everything from saving honeybees and tracking flu vaccine uptake, to aiding in the fight against bioterrorism, and plenty in between.
But machine learning can also be put to less-scrupulous uses just as easily. Social engineering is a type of cyber attack that deceives users into creating security breaches, typically through emails and phone calls (often called ‘phishing’), and the marriage of machine learning with social engineering is poised to be a burgeoning issue in the near future. This issue is a global problem, but developing markets are often at the highest risk for cyberattacks due to the lack of capacity to defend against and track such attacks. As such, they often find themselves as the testing grounds for novel attack methods before they reach more developed markets.
Lessons from the Fall Armyworm Tech Prize: The Importance of Ensuring Goals Align
One of the attractions of awarding prizes in global development is that the prize sponsor shifts the responsibility of achieving results onto competitors. While this approach can inspire a range of creative solutions and spur a nascent market, it also means many finalists will develop something valuable whether they win the award or not. For a prize to be valuable to both sponsors and competitors, sponsors must clearly communicate prize objectives so that competitors have the best chance at success and can assess whether devoting resources to achieve those objectives makes sense for them, win or lose.
The (Missing) Digital Principle: Educate the User
We in the international development community talk a lot about privacy and security in digital development. We try to think through privacy and security in terms of the data we collect, what we do with it, and even how we address issues of consent around data collection. There’s an entire digital principle about it.
In discussions like these, privacy and security are framed entirely in terms of the paradigm of extraction—collecting and gathering data from end users to organizations. This is an entirely valid and important discussion to continue having. However, there’s a discussion we’re not having that’s arguably even more important, and that’s around the privacy and security of users.
Working in Agriculture? Using Digital Ag Tools? Please Fill Out This Survey!
The U.S. Agency for International Development (USAID) has worked with Missions to integrate digital tools and technologies into Feed the Future activities since 2015, first through the U.S. Global Development Lab-led Digital Development for Feed the Future(D2FTF) initiative and now through the Bureau for Food Security (BFS) (BFS). BFS works with DAI’s Digital Frontiers project, a buy-in mechanism that allows Missions to receive digital solutions for resilience and food security assessments as well as program, project, activity design, and implementation support.

Photo credit: CABI
As part of this work, DAI-led Digital Frontiers is conducting a survey of agriculture projects to understand their experiences using digital tools in their work. These findings will be used to inform BFS’s digital strategy. If you are working on an agriculture project, we are very interested in hearing from you.
Please take 10 minutes to fill out our survey.
We thank you in advance for taking the time to complete this survey.
Questions? Please email [email protected].
Access as an Assumption: The Unintended Consequence of Increasing Digital Access
 In our quest to increase digital access, we tend to focus on the dividends, rather than the negatives that can arise. We are understandably excited about edging closer to universal access and the new business opportunities and improvements to service provision that accompany it. But while we are improving in our endeavor to promote online safety and security, bridge the gender digital divide, and include people with disabilities (all great stuff!), we could be overlooking some negative consequences of increased digital access.
In our quest to increase digital access, we tend to focus on the dividends, rather than the negatives that can arise. We are understandably excited about edging closer to universal access and the new business opportunities and improvements to service provision that accompany it. But while we are improving in our endeavor to promote online safety and security, bridge the gender digital divide, and include people with disabilities (all great stuff!), we could be overlooking some negative consequences of increased digital access.
How Digital Tools Help Combat Illegal Mining and Logging in the Amazon
A recent report prepared by the Amazonian Geo-referenced Socio-Environmental Information Network (RAISG) and InfoAmazonia, in coordination with eight other Latin American institutions, published a map that shows more than 2,000 data points across the Amazon where illegal activity is occurring. This includes illegal mining and logging in 96 protected areas. Most of the illegal activity is taking place in Venezuela where there are a reported 1,899 data points documenting illegal mining or logging. Venezuela is followed by Brazil where 321 cases of illegal activity are recorded. In Ecuador, the number drops to 68, and in Peru, 24. For organizations, governments, or advocates looking to protect the Amazon, this digital tool seems like a blessing. Yet, based on my experience it’s unclear whether these information-streamlining tools are actually limiting illegal activity.
A Resolution to Support the Tech Sector Where We Need It Most
On January 5, I posted the message below on Facebook to hold myself accountable to my New Year’s resolution.

It’s simple. I want tech businesses to grow and thrive in Nigeria outside of Lagos. I want to support someone who grew up in, works in, and wants to continue working in my hometown, Uyo. This is not just my resolution, but has been my life’s work since I started Start Innovation Hub five years ago. Start Innovation Hub is an ICT firm and innovation lab that works to expand the tech industry by supporting tech startups and talented individuals in Uyo. We build skills and connect entrepreneurs to economic opportunities, as well as support local businesses by developing software solutions. You can’t deny that the tech sector in Nigeria is growing rapidly, but the concentration of firms in Lagos means that places like Uyo are left behind. Through Start Innovation Hub, I hope to change that.
The Four Rs: An Interview With the Lean Research Initiative
We are huge fans of the Lean Research initiative at DAI’s Center for Digital Acceleration. I recently went to the Massachusetts Institute for Technology’s MIT D-Lab and sat with Elizabeth, Kendra, and Kim, the team behind Lean Research, to learn more about the genesis of the initiative and what tools and resources they offer ICT4D practitioners eager to “right-size” their own research approaches.
6 Tips for Making Great Monitoring and Evaluation Dashboards
Technology and data are converging in ways that allow monitoring and evaluation (M&E) professionals to more effectively monitor, evaluate, learn, and adapt on their projects. Dashboards are one of the key tools contributing to this trend, having become more accessible and user friendly through platforms such as Microsoft PowerBI.
Dashboards are an information management tool that visually track, analyze, and display metrics and data points to monitor the status of a project. DAI is creating dashboards for all new projects to enable teams to learn, evaluate, and adapt to project realities in near real-time. Ultimately, these dashboards make for better monitoring and evaluation and—in turn—better projects. Therefore, it’s important to get it right. So where should you start?
Frontier Insights: Cyber Security Edition
The headline says it all: “Over a billion people’s data was compromised in 2018.” Among the most egregious offenders were some of the most popular tech platforms in the world: Facebook, for example, admitted it had leaked the personal data of nearly 150 million users; Twitter leaked the passwords of nearly all 330 million of its users; and even mighty Google had two of its products hacked: Firebase (an app monitoring tool) leaked the data of more than 100 million users, and Google+ leaked 500,000 users’ personal info.
Looking Ahead: What We’re Thinking About in 2019
In our last post, we reviewed our top posts of 2018. The most-read articles covered a lot of ground—from Fortnite for development to digital lives in rural Malawi to making your own chatbot. We equally expect 2019 to be full of interesting projects, engaging conversations with colleagues, and, as always, meaningful opportunities to keep learning and doing better, more impactful work.
Here are a few topics we’re thinking about as we dive into the year. Let us know if you want to collaborate as we explore where they’ll take us—and stay tuned to our blog for updates throughout the year!
Digital@DAI Year in Review: Top 10 Posts of 2018
This year, Digital@DAI published more than 50 posts covering everything from women’s entrepreneurship in Cambodia to cyber security for development to smartphone apps for fisheries in Central America.
We featured digital experts from organizations such as John’s Hopkins University, Simprints, Every1Mobile, Humanitarian OpenStreetMap Team (HOT), and Panoply Digital, and generated nearly 47,000 page views. The blog continues to explore the potential of digital technology across sectors, geographies, clients, and constituents, reflecting the work that we do. As we continue to engage with all of you—and with the ICT4D community through DAI’s Center for Digital Acceleration (CDA)—our focus on research and products will expand as we ensure that our field-focused deployments of digital solutions are responsible, inclusive, and dynamic.
In our final post of 2017 we reviewed the 10 most-read articles of the year. With our audience and number of blog posts continuing to grow, we now present our top 10 for 2018. These posts showcase a range of topics, content, and writers. Going into 2019, we hope you will connect with us, read the blog, and subscribe to Digital@DAI so you don’t miss any updates in the coming year.
An Embarrassment of Riches
Years ago, yours truly was struggling with a major life decision, one that had led to many a sleepless night: Where to go to grad school? I’d been accepted into a number of programs and was agonizing over my options. My dad had graciously taken on the role of my sounding board until one day he blurted out in frustration, “you have an embarrassment of riches, Rachel. Just decide!”
Cyber Security Series Part 3: Pirated Software
It’s been about two months since I last contributed to the Cyber Security Series, but don’t let the time fool you into thinking we haven’t been engaging extensively on the topic. As many of you might remember, the Center for Digital Acceleration (CDA) published the Digital Inclusion and a Trusted Internet report in October on the topic. For those of you who have not read it, I highly recommend it, particularly if you’re interested in cyber security or data privacy.
The first post in this series focused on the issue of trust and the second post argued that investment in regulations that support the enabling environment, strong institutions, and skills of the population are key to integrating cyber security across a country’s economy. This post focuses on a more micro-level challenge—pirated software—and how addressing it is key to responding to cyber security overall.
Data, Analysis, and Information (Not as Boring as It Sounds)
If you aren’t excited by the headline—you should be! In this blog I will highlight a few issues I run across when discussing projects or planning data analytics solutions. Going into the details of each of them would take quite some time, so I will keep the anecdotes (data?) brief. There will undoubtedly be many interpretations of the data -> analytics -> insights/information flow, but this blog is simply an opportunity for me to share my own thoughts. After all, what are we as good data stewards and scientists without proper debate?
Coming Soon: Global Digital Health Forum 2018 & ICT4Drinks
The Global Digital Health Forum—an annual meeting of health-focused government stakeholders, technologists, researchers, and donors from across the globe—is coming up December 10 through 11.

Three experts from DAI’s Center for Digital Acceleration will be featured at five separate events, so come find us! Full list below:
Powering Women’s Entrepreneurship in Cambodia
 Meet Lida Loem. Lida is the co-founder of SHE Investments, a social enterprise that helps Cambodian women turn their entrepreneurship skills up to 11 (yes, out of 10) with training, mentorship and networking in both cities and rural regions of Cambodia.
Meet Lida Loem. Lida is the co-founder of SHE Investments, a social enterprise that helps Cambodian women turn their entrepreneurship skills up to 11 (yes, out of 10) with training, mentorship and networking in both cities and rural regions of Cambodia.
SHE’s vision is a world where investments in women in developing countries are seen as opportunity, not charity. They work with current and aspiring entrepreneurs across Cambodia, and see themselves as a catalyst for women’s economic empowerment through increased income generation and employment opportunities. Their work helps to bridge the gender gap in business and entrepreneurship, strengthening and diversifying Cambodia’s economy.
Human-Centered Design for a Digital Farmer Business School Application: A One-Day Roadmap
Human-centered design (HCD) is a central focus of DAI’s. We’ve written extensively about how we work with our partners to follow this complex and time-consuming (but very important) process and even came up with a more concise, budget-friendly Lean HCD approach.
As part of our continued commitment to the approach, Karim Bin-Humam and I recently traveled to Ghana to run a workshop on HCD for the Sustainable Smallholder Agribusiness Programme (SSAB), implemented by Deutsche Gesellschaft für Internationale Zusammenarbeit (GIZ) GmbH.
This was lean HCD on steroids: We asked participants to produce a HCD roadmap in just one day.
Participants chose their methods from the ideo.org design kit.

Meet the 9 WomenConnect Winners Who Are Using Tech for Good
Choosing just nine shining examples from more than 500 applicants of the U.S. Agency for International Development (USAID)-funded WomenConnect Challenge was no easy task. The global call—put out in March by Ivanka Trump and USAID Administrator Mark Green—sought examples of the changing ways in which women and girls’ access and use of technology help drive quality health, better education, and improved livelihoods for themselves and their families.

Digital Inclusion and a Trusted Internet
 Back in 2014, when I was leading USAID’s Digital Inclusion Practice, I was invited by the U.S Department of State to present on the importance of information and communication technology (ICT) in driving economic growth. The cyber training was intended to equip foreign service officers with the knowledge and tools to represent the broad range of policy priorities enumerated in the President’s International Strategy for Cyberspace: Prosperity, Security, and Openness in a Networked World.
Back in 2014, when I was leading USAID’s Digital Inclusion Practice, I was invited by the U.S Department of State to present on the importance of information and communication technology (ICT) in driving economic growth. The cyber training was intended to equip foreign service officers with the knowledge and tools to represent the broad range of policy priorities enumerated in the President’s International Strategy for Cyberspace: Prosperity, Security, and Openness in a Networked World.
Getting the Basics of ICT4D Right
There’s a tendency in any field of business (and life!) to focus on the newest, shiniest objects. Just like obsession over the release of the latest iPad, the ICT4D community holds a special place in its heart for the newest technology offerings. Machine learning, blockchain, and the internet of things (IoT) come to mind today, whereas in years past it was crowdsourcing, social media, or smart phones.

Financial Sector Deepening Mozambique: The Regulatory Sandbox Startups
All over the world, digital tools are creating opportunities for the those without bank accounts and expanding the array of financial services, known as fintech.

The Financial Sector Deepening project is increasing financial inclusion in Mozambique.
Mozambique is no exception—whilst literacy rates there are low, and the ICT infrastructure and regulatory framework are underdeveloped, traditional banking is still not serving people’s needs. The financial inclusion rate is at 42% (Work Bank Findex 2017) and there is a clear need for financial services to be available for poorer, more rural and marginalised populations.
Business Concepts from KIC’s 2018 Agritech Entrepreneurs
The award-winning Kosmos Innovation Center in Ghana has completed its final round of pitches for the 2018 cohort, and as with previous years, the program’s (very) early-stage young entrepreneurs continue to impress. Unlike previous years, the eight finalists this year were given six weeks and a small stipend to develop their minimum viable products (MVP), in addition to nine months of KIC-funded capacity building and market research. This meant that each team had the chance to meet with users, tweak their revenue models and designs, and even raise revenue to demonstrate proof-of-concept. As a result, I found that this year’s teams were well ahead of their 2017 and 2016 counterparts—their pitches were more compelling; they were more confident in their ability to answer judges’ questions; and their nose for entrepreneurship opportunities was keener.
Here’s a run-down of each team’s business concepts for technology-driven Ghanaian agribusinesses.
Cyber Security Series Part 2: Understanding Cyber Security as Part of the Digital Development Conversation
In our first post in the 2018 Cyber Security Series, I discussed why cyber security should be a key consideration in the design of digital tools that help support sustainable development efforts. I highlighted that trust in digital tools should not be taken for granted, but rather constantly invested in by designing digital tools with user input, but also with security in mind. Now I will take a look at some of the other key analog complements that need to be considered when deploying secure, integrated digital systems for sustainable development.
DFID and DAI Host Malawi’s First Digital Development Forum
Over the last few weeks, DAI’s Center for Digital Acceleration has been working closely with the U.K. Department for International Development (DFID)’s Malawi office to conduct a digital scoping study of its portfolio. Building on some of the user research we’ve conducted in Malawi, we’re identifying areas where DFID can make small, focused investments in digital innovations to improve the impact of its programs. And we’re also helping the team build relationships with the small, but growing, group of Malawian technologists tackling development challenges with digital tools. As part of this effort, we put together DFID’s first-ever Malawi Digital Development Forum last week, which brought together local technologists, development implementers, government decision-makers, and DFID staff for a day-long technology exchange.
Fishing with Smartphones
Much has been written about the digital divide and the failure of ICT to meet the needs of the poorest users. As World Bank President Jim Kim says, “We must continue to connect all people so that no one is left behind … because the loss of opportunities has a very high cost.”
In Central America, some of those ‘left behind’ include more than 135,000 fishermen. Without access to vital information about how climate change affects fishing, their very livelihoods are under threat.
The Americas’ Effort to Integrate, Distribute, and Use Open Data to Make Decisions
I was happy to represent DAI’s Center for Digital Acceleration at AmeriGEOSS week recently in Brazil, sharing experiences of how DAI has developed platforms and tools for decision-making in Central America.

Kosmos Innovation Center wins 2018 P3 Impact Award
We’re so excited that the Kosmos Innovation Center—the Kosmos Energy-funded project DAI helps implement in Ghana—was announced the winner of the 2018 P3 Impact Award at the annual Concordia Summit in New York, that takes place alongside the United Nations General Assembly.
Cyber Security Series Part 1: Trust is Why Cyber Security Matters to Digital Development
We’re launching one of our final series for 2018 on cyber security with this post on why it matters to international development. Stay tuned and subscribe to our newsletter if this topic interests you!
Thinking About the User Part I: Design Considerations for Mobile Apps
Think back to the last time you used a mobile app(lication) with unwieldy menu placement, indecipherable icons, and inconvenient user-configurable options. These may seem like minor nuisances in the everyday life of app interaction, and frankly, most users probably never notice (or maybe don’t realize that they notice) or hardly care. But user experience in application design is critical to ease of use, efficient navigation, and longevity of mobile-based application technologies.
Fortnite for International Development?
Fortnite—a free, online multiplayer video game—has amassed more than 125 million players worldwide during the mere 14 months since it debuted in July 2017. The game features a fast-paced, Hunger Games-inspired format mixed with community, celebrity, and story, and so far it’s working. Everyone from athletes to musicians are going public with their fandom and some parents are shelling out $35/hour for a Fortnite coach for their kids.

Image © 2018, Epic Games.
August Roundup: Leapfrogging Technology, ICT4E in Conflict, and Facebook in Myanmar
Ah, the dog days of summer. Usually a slow time for work, that means there’s extra time to sit at your computer looking for good stuff to read, struggling with either being uncomfortably warm from the summer heat or excruciatingly cold from over-aggressive office air-conditioning. We get it. We got you. Fresh ICT4D reads from our August Roundup below!

5 Top Resources for Digital Access Data

The global community has recognized the importance of digital equality—affordable, universal internet access as one of the Sustainable Development Goals. When we are implementing digital programs, access and inclusion are key concerns: We don’t want to leave anyone behind.
The Rising Tide of ICTs for Accountability
A tectonic shift is taking place in commerce, and we’re all a part of it. At its core, it boils down to one concept: accountability. The accelerating movement toward web-based management tools, data analytics, and automation among businesses—coupled with the rapid growth in mobile phone technology—has reduced the cost of doing business, slashed barriers to entry, and reduced the time elapsed from concept to market-ready solution. The result is increased competition, more customer choice, greater accountability to the customer, and the sound of the sledgehammer falling upon formerly protected industries. Customers in the many business-to-consumer verticals (admittedly not all) have more bargaining power than ever before, and can hold businesses accountable for poor performance by downloading a competitor’s solution with a few simple clicks.
Getting Started with RStudio, Part 2
This article is part 2 of a series exploring the basics of importing and analyzing data in RStudio.
In a previous post we introduced the R programming language, RStudio as a development environment, and examined rainfall data for May. The data we analyzed was stored in Google Docs. We used some functions to pull the data into our work environment, and displayed the data over time using a line graph. In this post, we’re going to make an improvement to this analysis. Specifically, we’re going to streamline the way we access weather data.
Essential Actions: A Human-Centred, Global Approach to Privacy Rights
We’ve read the headlines: large-scale breaches of highly sensitive information in the United States, in the Philippines, in Nigeria, in India … the list goes on. The message is consistent: somebody, somewhere, needs to do something to protect us. Enter the General Data Protection Regulations (GDPR), the EU’s (in)famous answer to protecting the personal data of its citizens. Some applaud it as the world’s strictest privacy standards; others consider it outdated from the start. (We’re in the age of blockchain and AI; you tell me how to exercise right to erasure here.) Either way, GDPR concepts are useful to international development contexts.

Coffee Cloud: El proyecto digital para los caficultores de Centroamérica
Del 2010 al 2014, el grano de café de América Central sufrió una enfermedad que sacudió las economías de la región. Las exportaciones disminuyeron en un 55 por ciento. De 2012 a 2013, se perdieron 374,000 empleos correspondiente al 17 por ciento de la fuerza de trabajo. La Roya, o roya del café, amenazaba los medios de subsistencia de casi 2 millones.
Take it to the Farmer: Behind the Scenes of the Fall Armyworm Tech Prize Co-Creation
Along with human-centered design and lean startup, co-creation is an approach arising to prominence in the development lexicon over the past five years. Some of us (myself included) have used “co-creation” without understanding what it means, simply assuming it was an event that brings together a variety of partners to brainstorm ideas to solve a problem. Only when I attended the Fall Armyworm Tech Prize co-creation workshop from June 26 to 29 in Kampala, Uganda, did I grasp the nuances of co-creation and realize the significant benefits it holds for the end users of co-created products.
A Time of Change. And Reflection.
I can’t remember exactly what I was doing when the grenade went off up the street—probably brushing my teeth or something mundane like that. I was halfway through my two-week visit to Ethiopia and looking forward to getting out in the field. I was also completely unaware of what had just happened. It was a sobering day. I spent all afternoon watching the news. First one person confirmed dead, then two. One-hundred and fifty or so wounded. Fear on the faces of a populace that had recently been so full of hope.

Image credit: AddisBiz.com
DAI’s Center for Digital Acceleration Featured on Podcast
This is HCD—a podcast that explores what human-centered design (HCD) looks like in practice—featured DAI’s Center for Digital Acceleration work in Guatemala on its most recent episode.
Digital Health in International Development: Using Tried & Tested Technology Innovatively

I recently took part in the DAI panel discussion on “Digital Health in International Development: Current Realities and Future Trends” in London. It delivered fascinating perspectives from across the health, tech, and development sectors. Here’s a few key points I shared during the discussion and hope to stimulate a continued conversation.
Deadline Extended! Apply Now: Support USAID Missions to Improve Broadband Connectivity
DAI’s Digital Frontiers project has extended the deadline to July 3 for proposals from interested organizations to help the U.S. Agency for International Development implement the Better Connectivity, Better Programs: How to Implement a Demand Aggregation Program (How-to Guide). The initial Request for Proposals (RFP) and related information can be found here.
Answers to RFP questions were emailed to interested offerors and can be found here.
Have questions? Email [email protected].
Catching Up with the Winners of MIT’s Grand Hack for Health
Let me start by saying that the Massachusetts Institute of Technology’s (MIT) Grand Hack is kind of a big deal. I don’t make the point as an affront to other hackathons—certainly not DAI’s own—but not many other hackathons can claim to have generated more than $150 million in venture capital and spawned more than 40 viable companies. Those two facts qualify the Grand Hack for royalty status among hackathons, which makes it even more surprising that the event is run entirely by students, MIT’s Hacking Health group. It’s also the reason why I was so excited to get a taste of MIT’s secret innovation sauce from the inside—as a mentor, alongside my colleague Kristen Roggemann.
Coffee Cloud: The Digital Project for Central American Coffee Growers
From 2010 to 2014, the Central American coffee bean suffered from a disease that rocked the economies of the region. Exports declined by 55 percent. From 2012 to 2013 some 374,000 jobs were lost—17 percent of the labor force. Roya, or coffee rust threatened the livelihoods of nearly 2 million.
Coffee rust is a fungal disease that covers the leaves and prevents photosynthesis, slowly constricting plants’ ability to process sunlight, reducing bean yield and eventually starving the plant to death. The warmer, wetter conditions wrought by climate change creates a better ecosystem for the fungus to grow. Its impact on Central American economies is significant as coffee exports are the region’s largest source of foreign income and coffee supports a vast supply chain, in turn supporting dozens of adjacent industries.
Trends in Digital Health: 4 Takeaways From Our UK Event
In comparison to other development sectors, health programs have historically been early adopters of digital tools. What have we learned over the last 10 years, and where are we heading? How can we build systems that integrate data from independent actors across the health ecosystem? How can we use lessons learned to support innovation? How can we adapt to expanding digital access and support the growth of local capacity?
Apply Now: Support USAID Missions to Improve Broadband Connectivity
The rapid expansion of mobile and internet access in the developing world holds the promise of catalyzing resilient economic and social growth. However, the availability and cost of connectivity is a significant barrier to fully realizing that vision.
To help address this challenge, the U.S. Agency for International Development (USAID)’s Center for Digital Development developed the Better Connectivity, Better Programs: How to Implement a Demand Aggregation Program (How-to Guide).
Working With Tech Service Providers: It’s About More Than Tech
Are you a nonprofit focused on improving maternal health outcomes? Or maybe you’re a civic engagement organization that encourages young people to become more involved with their local governments. No matter the objective, technology can both help you be more efficient internally and more impactful externally. The idea of tech is often easy: “Oh, we’ll just build an app for that!” But relationships with technical service providers are fraught with pitfalls that can jeopardize outcomes and derail even the best intentions.
5 Recent Reads We Loved (And You May Have Missed!)
As our Center for Digital Acceleration team grows, we are finding new ways to share knowledge beyond our epic WhatsApp group chat that grows more ridiculous and off-topic by the day. We have some voracious readers on the team, so in prep for this post I took a minute to poll them to find out which recent articles they found fascinating—and I had missed them all! Since I can’t be the only one, I am sharing them with you to ensure these gems get as wide a readership as possible.

Replicando la App de Transparencia en Guatemala
Note this post is also available in English
El pasado mes de febrero del año en curso, retorné a Guatemala con el fin de dar seguimiento a una iniciativa tecnológica denominada Somos Chiantla, que promueve la participación ciudadana y la rendición de cuentas en el municipio de Chiantla, en el departamento de Huehuetenango. De igual manera visité los municipios de Sacapulas y San Rafael Pie de la Cuesta, con el fin de replicar esta herramienta en estos dos municipios, con un enfoque eminentemente participativo y colaborativo, considerando propuestas de autoridades de gobierno local y representantes de la sociedad civil para personalizar la aplicación atendiendo a sus gustos y preferencias.

Un participante en Sacapulas vota por las mejores formas de actualizar Somos Chiantla.
Getting Started With RStudio, Part 1
This article is part 1 of 2, as we explore the basics of importing and analyzing data in RStudio.
As a data scientist, I spend a lot of my time working in a programming language called R. RStudio is an open source integrated development environment (IDE) for the R programming language, which focuses on programming for statistical analysis. You could arguably do data analysis in almost any computer programming language, but R offers some of the most accessible statistical functions of any language available today. You could also do this work in a business intelligence application such as Tableau or PowerBI, or conduct statistical analysis in STATA, but R and RStudio are free and open source. In this post, I’m going to introduce a few lines of code to get you started on your journey into R.
ICT4D Conference: Unpacking the Complexities of Integrated Health Data and Data Ownership
“We are at an inflection point in digital development!” Lauren Woodman, CEO of NetHope, boomed over the crowd of 750-plus participants the first day of the recent ICT4D Conference in Lusaka, Zambia. It may indeed be a critical time for technology, but the means of reaching our collective goals can create healthy disagreements, ones that should be unpacked in exactly the kind of setting the ICT4D Conference creates.
A Do No Harm Framework for ICT4D: Inspiration from SwitchPoint 2018
SwitchPoint 2018 was an inspiring, passionate, and delightful indulgence: Spending two days in lush Saxapahaw, North Carolina, thinking about big ideas and learning from leading experts in small group sessions in between performance art and live music shows felt like such a departure from Conference As Usual. I felt space opening up in my brain to start really processing what the speakers were saying—the real act and action of listening versus the usual ruse of secretly responding to emails on my phone while half paying attention and nodding at key pauses.
Digital Insights Malawi: Information and Communication in Rural Communities
Last month, I spent two weeks in Malawi trying to gain a real understanding of technology use and media consumption habits of people in rural and marginalised communities. Along with a team of enumerators, I spoke to 183 women, men, girls and boys (ages 14 to 80) in different traditional authorities (TAs) in Northern, Central and Southern Malawi.

Alice talking tech in Mponda, Mangochi, Southern Malawi.
TicTec 2018: Key Takeaways from the Impacts of Civic Technology Conference
Last week I was at MySociety’s annual civic technology conference, TicTec, in Lisbon. For anyone who couldn’t make it I unfortunately can’t share all the takeaways, like the delicious Pastel de Nata, but here are a few treats for the mind.
Forking a Live Tool with Design Thinking in Guatemala
Esta publicación también está disponible en español
This past February I was back in Guatemala, working with the fine people of Chiantla to improve and iterate Somos Chiantla. I was also in two new municipalities—Sacapulas and San Rafael Pie de la Cuesta—helping them create their own, personalized, forked versions of the app.
A participant in Sacapulas votes for the best ways to update Somos Chiantla
Writing Code is for Everyone—Now the Code Partners Scholarship Makes it Affordable
When someone needs a website or mobile app, they search for a coder. Almost anyone can be trained to write code and enter the digital workforce—once there, opportunities abound: from helping businesses, governments and other organizations build the websites and apps they need to supporting the digital systems that power economies worldwide.
Blockchain for Development Part 2: Implementation Considerations
As discussed in Part 1 of this two-part post on blockchain, “Understanding the Tech,” the blockchain hype is pervasive in international development these days. It is my view that blockchain does not deserve the “Swiss army knife of new technology” label that has been thrust upon it. While blockchain is exciting and potentially very useful, appropriate application of the tech can be evasive. If you need a quick and simple run down of blockchain, check out Part 1. Here I will give you a glimpse of some of the potential uses for blockchain in global development programming, and some of the challenges.
Submit Your Session Ideas for ICTforAg 2018
As in previous years, DAI is co-sponsoring this year’s ICTforAg conference in Washington, D.C. The conference is on June 14 at FHI 360. The conference is now accepting submissions for lightning talks and breakout sessions here. The deadline for submission is April 13. Use the guiding questions below to shape your session ideas, and see you all in June!

Blockchain for Development Part 1: Understanding the Tech
Bitcoin has launched the term “blockchain” into the world’s tech vernacular. Unfortunately for blockchain as a technology and a theory, it is often, for better or worse, synonymized with Bitcoin. Because of this, the ideas of public, transparent, and unchangeable information immediately come to mind as soon as someone mentions blockchain. While this is true for Bitcoin, this is not necessarily the case for all blockchains.
Putting Liberian Cities on the Map With OpenStreetMap
As the world becomes more urbanized, data on cities and the residents who inhabit them is key to building and governing sustainable communities. Yet this data is simply not available for many rural and urban areas around the world. Many cities lack base data sets—such as accurate maps of their cities that identify key infrastructure, services, and human settlements. In some cases, these maps exist on paper, but in other cases, are only available in closed, proprietary systems or not at all. This was the case in the Liberian cities of Ganta, Gbarnga, and Zwedru.
How a Pilot Project in Haiti Brings Optimism for Digitally Enabled Health System
I recently presented during a TechChange course titled “The Future of Digital Health.” I was asked to discuss the implementation of the Haiti Strategic Health Information System (HIS) program, a five-year, U.S. Agency for International Development-funded initiative that is consolidating and integrating Haiti’s disconnected health information assets. Preparing for this presentation gave me a chance to reflect on the past year—the progress we have made, the challenges we have encountered, and the future of digital health in Haiti.
How to Engage and Support Local Innovators: 3 Takeaways from the Digital Development Forum
On March 9, I moderated a workshop called “How to Engage and Support Local Innovators” at the USAID Digital Development Forum. I was joined by three expert panelists: Danielle Dhillon from the Digital Impact Alliance (DIAL) at the UN Foundation; Toni Eliasz from the World Bank’s Digital Entrepreneurship Program; and Tyler Radford from the Humanitarian OpenStreetMap Team (HOT). All three are focused on nurturing local technologists and innovators. Toni and Danielle support local startup ecosystems and Tyler builds communities of volunteer mappers. What have they learned through these efforts?

Playing The Right Role In Haiti’s Growing Mobile Sector: 4 Key Principles
Digital financial services have been a robust part of the development sector for over a decade and their impact continues to grow. This blog post is part of a series produced by mStar that focuses on successful projects that achieve results-driven impact in people’s lives. This post was originally published on the mStar digital development blog.

It’s an exciting time for mobile money expansion in Haiti. Digicel’s MonCash—Haiti’s largest mobile money deployment—has reached nearly 1 million customers and $400 million in yearly transacted value in 2017. This customer base represents a +1500 percent increase from 2015, the same year Digicel rebooted its strategy, marketing approach, product offering, and sales and training force.
Getting ICT Into the Hands of More Women
March 8 is International Women’s Day! To celebrate, we’ll look at a course on women and ICT inclusion developed by USAID Digital Inclusion, mSTAR, and Panoply Digital. Click here to access the course.
ICT for Citizen Engagement and Advocacy: Lessons Learned from Mozambique DIÁLOGO
The Mozambique Democratic Governance Programme, DIÁLOGO, funded by the U.K. Department for International Development, worked with citizens, civil society, local media, and municipal government to engage more effectively on local issues. DIÁLOGO supported innovative solutions, including mobile- and web-based technologies, to amplify the voices of citizens and help governments respond to their demands. The programme ran from 2012 in the five urban municipalities of Beira, Maputo, Nampula, Quelimane, and Tete, and ended last December.
DFID’s Digital Strategy: What Does it Mean for DAI?
Last month, the U.K. Department for International Development (DFID) launched its much-anticipated Digital Strategy 2018-2020: Doing Development in a Digital World, outlining its vision and approach towards using technology to have a bigger, faster, and more cost-effective impact on the lives of poor people—particularly those who are marginalised.
Getting Past the Blockchain Hype Cycle
Distributed Ledger Technologies (DLTs), commonly referred to as blockchain applications, are possibly the most talked about innovation of the day. And the most commonly discussed DLT applications are those that involve financial transactions with cryptocurrencies. Fortune Magazine recently listed “The Fintech Renaissance” as the second-most important technology trend of 2018, and with good reason. Last month Bitcoin saw more than 400,000 transactions per day. Despite warnings of Bitcoin’s volatility, the increased investment in cryptocurrencies is hard to ignore.
But what about all of the other promises of DLTs? There are no shortage of articles written about their impact on data security, the value of smart contracts to create efficient online transactions, and the value of data democratization and transparency through shared ledgers. While there are case studies for each of these promising areas, distributed application developers are in short supply, and active implementations for global development projects are rare. As a result, I get the sense that blockchain may be entering the peak if its hype cycle.
Why is DAI Investing in a Coding School?
DAI and Rockville, Maryland-based United Solutions recently launched a business called Code Partners to provide classroom instruction in software development. Code Partners will rely on the proven curriculum and teaching methods of Seattle-based Code Fellows, starting with beginner-level courses in HTML, CSS, and JavaScript.
“S3” Site Selection System: A Data-Driven Decision-Making Tool for Effective Engagement
Recently while on assignment in Haiti, a project manager for a local agricultural development project asked my team why we weren’t targeting certain rural communities. According to him, those communities are the ones that could really benefit from the type of work we were doing. While we had good reason to work where we were working, the question stuck: How can we be certain that we are targeting the right communities?
We Don’t Need to Reinvent the Wheel, But it’s Time to Invest in Roads and Highways
Here’s the good news: Over the past 10 years the digital health community has begun to heal from a severe case of pilotitis. As a community of innovators and health systems researchers, we increasingly recognize that creating and testing new digital health tools in the absence of investments in the enabling ecosystem is likely to produce limited, short-term, and small-scale impact. Without concerted efforts to fertilize the soil in which the seeds of innovation are planted, those seeds will never mature beyond a sapling. That is, unless we pay attention to the policy and regulatory environment, the telecommunications and electrical infrastructure, and most importantly, the availability of trained and appropriate human resources to facilitate scale-up and sustainability, we cannot expect national-scale digital health projects to thrive.
KIC Expands its Support of Tech-Driven Entrepreneurship to Mauritania
Regular readers of Digital@DAI will know that we’ve been supporting Kosmos Energy’s Innovation Center (KIC) in Ghana for the last two years. KIC’s work with young tech entrepreneurs in the agricultural sector has garnered awards and plenty of media attention, and Kosmos is now looking to apply what it has learned to a new country: Mauritania.
Looking Ahead to 2018
The new year provides a great opportunity to think about priorities for year ahead. Last week we wrote a post highlighting the top posts of 2017. The most-read articles covered a lot of ground—from reflections on specific projects, to advances in our thinking on best practices for human-centered design (HCD), to technology reviews. So, what’s on our minds for the year to come?

Lean HCD: How to HCD When You Can’t Travel to the Field
Back in late 2015, I landed a unique design gig. The job came via Nexos Locales, a USAID-funded, DAI-run project that works with municipalities around the Western Highlands of Guatemala to improve public financial management and citizen engagement. A newly elected mayor in the municipality of Chiantla wanted to open his finances to the public to close the space for corruption, and I was asked by the project to scope out the activity.
Q&A Responses: Looking For a Partner to Fight Fall Armyworm
On December 7, DAI released a request for proposals (RFP) for a prize implementation partner to confront fall armyworm. This partner will join DAI and the U.S. Agency for International Development (USAID) in designing a results-driven prize to find digital tools and services that help smallholder farmers across sub-Saharan Africa. Thank you to those who asked questions about the RFP. We have reviewed your questions, and provided answers to each below.

GeekFest 2017: Talking Gender-Disaggregated Data with Alex Tyers, Panoply Digital
 Welcome to GeekFest 2017, a series of interviews featuring ICT4D thought leaders. Our goals for our #geekfest2017 interviews are 1. to highlight the people and organizations who are pushing the field in new directions, 2. feature their work and show how it’s different or new, and 3. to support the overall growth of the ICT4D community.
Welcome to GeekFest 2017, a series of interviews featuring ICT4D thought leaders. Our goals for our #geekfest2017 interviews are 1. to highlight the people and organizations who are pushing the field in new directions, 2. feature their work and show how it’s different or new, and 3. to support the overall growth of the ICT4D community.
 This week I chat with Alexandra “Alex” Tyers, Co-Founder and Director at Panoply Digital. Alex is a mobiles for development (M4D) professional, specializing in monitoring and evaluation for innovation, mobile learning in emerging markets, and women’s mobile and ICT access and use. Alex recently spoke at our Frontiers in Digital Inclusion Event in London on the importance of gender-disaggregated data for digital access and inclusion.
This week I chat with Alexandra “Alex” Tyers, Co-Founder and Director at Panoply Digital. Alex is a mobiles for development (M4D) professional, specializing in monitoring and evaluation for innovation, mobile learning in emerging markets, and women’s mobile and ICT access and use. Alex recently spoke at our Frontiers in Digital Inclusion Event in London on the importance of gender-disaggregated data for digital access and inclusion.
Apply Now: Looking For a Partner to Fight Fall Armyworm
Today, DAI releases a request for proposals for a prize implementation partner to confront fall armyworm head on. This partner will join DAI and the U.S. Agency for International Development (USAID) in designing a results-driven prize to find digital tools and services that help smallholder farmers across sub-Saharan Africa.
A farmer in Ethiopia inspects his fall armyworm-infested maize. (Photo Credit: FAO/Tamiru Legesse)
GeekFest2017: A Discussion with Cassandra Mickish Gross
Welcome to GeekFest 2017, a series of interviews featuring ICT4D thought leaders. Our goals for our #geekfest2017 interviews are 1. to highlight the people and organizations who are pushing the field in new directions, 2. feature their work and show how it’s different or new, and 3. to support the overall growth of the ICT4D community.
 This week I’m speaking with Cassandra Mickish Gross from the Johns Hopkins Center for Communication Programs to discuss the U.S. Agency for International Development (USAID)-funded Knowledge for Health Project. In this post Cassandra reflects on her experience developing a digital health platform. We explore the choice between an established solution with the potential to scale, versus one that has clear evidence of impact on health outcomes. During the interview, she reflects on the Faster to Zero Initiative, implemented in partnership with HealthEnabled, that aims to support the Ministries of Health of South Africa and Uganda in the scale-up of digital health tools and accelerate the elimination of mother-to-child transmission of HIV.
This week I’m speaking with Cassandra Mickish Gross from the Johns Hopkins Center for Communication Programs to discuss the U.S. Agency for International Development (USAID)-funded Knowledge for Health Project. In this post Cassandra reflects on her experience developing a digital health platform. We explore the choice between an established solution with the potential to scale, versus one that has clear evidence of impact on health outcomes. During the interview, she reflects on the Faster to Zero Initiative, implemented in partnership with HealthEnabled, that aims to support the Ministries of Health of South Africa and Uganda in the scale-up of digital health tools and accelerate the elimination of mother-to-child transmission of HIV.
3 Key Takeaways From Our London Digital Inclusion Event
Earlier this week, we were joined by Alex Tyers of Panoply Digital, Saloni Korlimarla of the Cherie Blair Foundation (CBF) for Women, and Guillaume Touchard from the GSM Association (GSMA)’s Connected Society Team at the delightful Makers Academy space in Shoreditch, United Kingdom, to discuss, debate, and engage around the challenges and opportunities for increasing digital inclusion and access.
DAI Launches 'Lean HCD: A Case Study in Human-Centered Design in the Highlands of Guatemala'
Today DAI launches Lean HCD: A Case Study in Human-Centered Design in the Highlands of Guatemala. This landmark report is the culmination of 18 months of close collaboration between DAI’s ICT team, the USAID Nexos Locales project, and the people of Chiantla, a municipality in the Western Highlands of Guatemala, to design a tool for budget transparency and citizen engagement.
Tailored Technology Enhances Resilience Programming
FHI360 recently hosted its annual Technology for Resilience workshop in Bangkok. In doing so, conference organizers created an opportunity for technologists and development practitioners to learn from active technology projects that promote community resilience, and work together on innovative solutions to what are often seen as intractable problems. In this post, I’ll look at some of the technologies showcased during the conference. But before doing so, let’s define resilience.

Cyber Violence Against Women and Girls Exacerbates Digital Exclusion
Raise your hand if you have experienced online harassment. I am sure the response is a virtual flurry. Although digital technologies have the ability to empower, connect, and liberalise, they can also serve as platforms for marginalisation and abuse.
5 Podcasts for Human-Centered Designers
In the field of international development, human-centered designers (HCD) are charged with rapidly developing empathy with a specific, targeted, marginalized population, diving into a social challenge which that group faces, and parlaying that understanding and access into a locally-tailored solution.

Doing so successfully requires one primary skill: listening. That means listening in the traditional sense: to an individual, as DAI does in our Digital Insights work. But, more broadly, listening for design in the international development space means listening to an entire population to identify social challenges as well as the cultural, political, and economic dynamics that affect them and perpetuate the problem.
Digital Insights: Would Haitians use Mobile Money for Banking?
In late September, I traveled to Haiti to conduct research on how Haitians engage with financial institutions and mobile technology to explore the feasibility of introducing mobile money as an avenue for the provision of financial services. Together with the team from the USAID/Haiti Finance Inclusive project, implemented by DAI, and with support from our sister USAID/Haiti project Finance Pour Tous and two key credit unions—Caisse Populaire Fraternite (CPF) and Socolavim—I visited nine locations through the northern and central provinces of the country to interview 181 credit union customers as they went about their business.
Why a Dashboard Isn’t Just a Dashboard
I distinctly remember an early conversation with colleagues when I began working in digital development in which a peer dismissively waved his hand at the idea of implementing a live data dashboard, saying “A dashboard is a dashboard is a dashboard!” The finality of that line stuck with me. I assumed that the dismissal came from a person who was bored with dashboards, like a kid who opens a birthday present to find he has received yet ANOTHER dashboard. Well, interactive data dashboards—just like automobile dashboards—may not be the newest, hottest, shiniest thing in the ICT4D toolbox, but they’re still important and their often hidden values go unappreciated by many.
8 Do’s and Don’ts in Adaptive Management and Learning in ICT4D
This is a guest post by Kate Heuisler, Chief of Party of DAI’s USAID-funded Cambodia Development Innovations project.
Development Innovations supports innovators and boosts the use of information and communication technologies for the overall development of Cambodia. The project is structured to be flexible and adaptive—because we need to. Really, most creative development programs should build themselves to be learning organizations, to be ready for big pivots, regardless if you and your partners use digital innovations. The development world is regularly disrupted—by political changes, natural disasters, new technologies such as social media—and is no longer built for static, five-year plans. Donors and funders need partners that can learn by doing, and are not afraid to adapt strategies and implementation plans to continually improve.
GeekFest 2017: Delving into Public Access with Duduzile Mkhwanazi of Project Isizwe
 Welcome to GeekFest 2017, a series of interviews featuring ICT4D thought leaders. Our goals for #geekfest2017 are: to highlight the people and organizations who are pushing the field in new directions, to feature their work and show how it’s different or new, and to support the overall growth of the ICT4D community.
Welcome to GeekFest 2017, a series of interviews featuring ICT4D thought leaders. Our goals for #geekfest2017 are: to highlight the people and organizations who are pushing the field in new directions, to feature their work and show how it’s different or new, and to support the overall growth of the ICT4D community.
This week we are focusing on public access as a solution to closing the Digital Divide. Being able to access free public wifi can be crucial for those who cannot afford internet subscriptions: It can be the difference between finally finding that job, getting the training you need or linking up with a valuable investor for your new venture. The 2017 A4AI Affordability Report noted the importance of public wifi for engendering use of the internet: Research shows public wifi as one of the most popular options for online access.
We sat down with Duduzile Mkhwanazi, CEO of Project Isizwe-an organization making great strides in providing free public wifi in South Africa, a country where inequality is rife and the affordability of mobile data is just out of reach for many, despite 99 percent 3G coverage.

Practicing the Principles for Digital Development in East Africa
This is a guest post by Mustapha Issa, Field Manager and MAST Coordinator and Gilead Mushaija, GIS Database Specialist, both from DAI’s Feed the Future Land Tenure Assistance project.
At the recent Practicing the Principles for Digital Development event on October 12 in Dar es Salaam, Tanzania, 80 participants from organizations including DAI, the Ministry of Works, Transport, and Communications, and private organizations from Ethiopia, Kenya, Malawi, Rwanda, Tanzania, and Uganda attended.
The Digital Impact Alliance (DIAL) and the Human Development Innovation Fund Tanzania (HDIF-UKAid) stewarded the event and were joined by leading organizations in endorsing the Digital Principles. DAI is a signatory to the Principles.
Three Key Takeaways from USAID’s New Gender and ICT Survey Toolkit
This past week USAID’s Global Development Lab and mStar project released the Gender and ICT Survey Toolkit. In an informative webinar (you can listen to the recording here), the team that produced the report discussed both the content and the context surrounding the genesis of the toolkit. I tuned in and spent the majority of the time silently cheering, thrilled to hear USAID promoting research tactics and information needs that align with what we on DAI’s ICT team are doing with our Digital Insights work. In between cheers, I feverishly took notes and captured these three key takeaways.
Testing Data Collection with OpenDataKit
Primary data collection: One of the most challenging, but necessary, components of any research project. Mobile and browser-based technologies have revolutionized the speed and efficiency of collecting data, enabling teams to work together on a centralized database without the headache of managing paper forms, or multiple excel documents.
If you’re reading this article, it’s likely you’ve used Googleforms or Survey Monkey for your work. But what if you need to collect data in regions without 3G or LTE coverage? You’ll need a tool to manage offline data collection, and load the data once you access a wireless internet connection. Fortunately, there are several tools designed to do just that, and one of them is completely free and open source. It’s called OpenDataKit (ODK). Let’s take a look at how this technology works.
Open Innovation in 60 Minutes or Less
When we do “open innovation,” it’s essential to define the problem we are trying to solve. And crucial to that process is crafting a good “Call.” Can this be done in 60 minutes or less?

DAI facilitated workshop on open innovation at the Triangle Global Health Conference in Raleigh, North Carolina.
The Second Chance Fund: Learning and Iteration with Tech in Cambodia
Any honest digital designer will admit it: Most tech tools fail. At least the first time around. Getting your users to drop the old way of doing things and use your new website (or gadget, or app) isn’t easy. It doesn’t matter if it visualizes their transactions in some really clever way, or sends their user data to the cloud for real-time analysis, or even if it saves them time or money. Behavior change is difficult, and doubly so when you’re designing across cultures. Why? A few reasons:
Investments in Internet Access Must Include Investments in “Critical Digital Literacy”
Expanding internet access in ‘last-mile markets’ is a priority for development agencies—and rightly so. The economic costs to countries that do not offer their populations internet access is high: Studies have detailed the internet’s macroeconomic boost to GDP, the economic and employment benefits of the growth in the digital sector, and the impact of ICT on small business revenue and job creation. Internet access has also been shown to improve learning and health outcomes and catalyze civic engagement. Reading these reports, it seems we’re in an all-hands-on-deck moment to get bandwidth into every last corner of the earth. But what about the risks?

Photo from Kenyan Daily Star
Catalyzing Ghana’s Growing AgriTech Ecosystem
This is the wrap-up piece for 2017 in our ongoing series about Kosmos Innovation Center (KIC) Ghana and its annual AgriTech Challenge, which DAI supports and helps implement. We’ll pick this series back up again for KIC’s 2018 cohort, but in the meantime, browse our KIC archives here, here, and here.
Open Source Series Part 3: Spatial Analysis with QGIS (Article 2/2)
In my last post I introduced QGIS, and previewed some of the basic functions in the upcoming release of Version 3.0. In this second of two articles, I’ll compare using QGIS in professional organizations to the use of proprietary software, and provide recommendations for organizations seeking to test the waters with spatial analysis. I’ve also reached out to three GIS professionals with experience integrating spatial analysis software into diplomatic and development work environments, and shared their perspectives in a Q&A section below.
![]()
Data Management Series Part 3: Painting a Vivid Picture with Data
Welcome back! After reading the previous two posts in this series, you’ve come a long way: you’ve devised a brilliant monitoring, evaluation, and learning plan, set up your data storage and management infrastructure, and conducted your baseline data collection. It’s finally time to get to the good stuff and dive into the data to make sense of it all—with eye-popping graphics worth of downtown billboards!

Data Management Series Part 2: Don’t Let Your Data Get Dusty
So, after reading last week’s blog, you’ve developed the world’s most robust monitoring, evaluation, and learning plan. You just conducted a multi-tier baseline assessment, validating your data by triangulating data points through five different surveying tools and are excited to dig in to multivariate regression analysis. But wait! First we need to talk about data storage and management!
In the international development world, an all-too-familiar sight is binders of data sitting idly on shelves in rural government offices. We all acknowledge that there are much better ways to store and maintain our results. However, many organizations only move one or two steps up the ladder: from paper and pen to .xlsx or .csv files on a laptop. While this may enable you to conduct the minimum analysis needed to satisfy your donor in an annual report, does it really maximize the value of the data we collect?

Data Management Series Part 1: Planning and Collecting
If you’ve been paying any attention to the so-called data revolution, you may have heard the expression “Data is the new oil.” The phrase has been attributed to and adopted by countless people and organizations to whom the central reasoning is clear: In the information age, data is an incredibly valuable “commodity.” The purpose of the analogy as originally made by mathematician Clive Humby in 2006 is significantly deeper though. He said that data is valuable, but cannot be used if it is unrefined. Like oil, data has to be changed, transformed, broken down, and analyzed for us to actually draw out the value locked within. This is true for anyone producing or accessing any type of raw datasets, including development organizations.
Open Source Series Part 2: Spatial Analysis with QGIS (Article 1/2)
In part one of this two-part article, we’ll explore the open source geographic information system (GIS) software package, QGIS, through a look at its history, and take a sneak peek at the upcoming release of Version 3.0, which is scheduled for release this fall.
![]()
There’s been a buzz around the release of QGIS version 3.0 for a couple of years now. QGIS has been my go-to desktop GIS application for the past five years, so I was thrilled to receive an e-mail from the QGIS LinkedIn user group with a link to beta test QGIS 2.99, a pre-release copy of the version 3.0. No hesitation there, it was finally a time to give it a whirl.
GeekFest 2017: Discussing Blockchain and Economic IDs with Shailee Adinolfi of BanQu
Welcome to GeekFest 2017, a series of interviews featuring ICT4D thought leaders. Our goals for #geekfest2017 are: to highlight the people and organizations who are pushing the field in new directions, to feature their work and show how it’s different or new, and to support the overall growth of the ICT4D community.
This week I’m speaking with Shailee Adinolfi, Vice President, Account Management and Marketing at BanQu. We discuss blockchain technology and its application to finance and commerce. For an in-depth primer on blockchain technology, we encourage reading this article in the Harvard Business Review.
Blockchain Summer News Round-Up: A Big Splash Into the Pool or a Dip of the Toe?
This is a guest post by Colleen Green, Senior Financial Sector Specialist at DAI and avid swimmer.
Blockchain technology has been in the news a lot this summer, and like the child standing at the edge of a swimming pool, the news is equal parts enthusiastic, cautious, and speculative about what lurks beneath.

Photo from the 2016 Blockchain Summit
Lanzamos ‘Somos Chiantla’, App de Transparencia, en Guatemala
Note: This post is also available in English.
Nota: Esta entrada es la continuación de una publicación anterior que explica nuestra fase de diseño digital, que fue centrada en los ciudadanos de Chiantla.

El 25 de mayo, el Alcalde Carlos Alvarado Figueroa anunció desde el Teatro Municipal de Chiantla el lanzamiento de Somos Chiantla, una aplicación móvil para la transparencia presupuestaria municipal y la participación ciudadana de Chiantla, uno de los municipios apoyados por Nexos Locales y ubicado en el Departamento de Huehuetenango.
Results of HCD: Governance App Launches in Guatemala
Nota: Esta publicación también está disponible en español
Note: This blog post follows an earlier post which covers our pre-development human-centered design phase.
On May 25, Mayor Carlos Alvarado Figueroa stood on stage at the local municipal theater and announced the launch of Somos Chiantla—a mobile app for municipal budget transparency and citizen engagement for the citizens of Chiantla, a town in the Western Highlands of Guatemala and one of Nexos Locales’s partner municipalities.
Human-Centered Design for Behavior Change in Health
One of the largest barriers to improving health outcomes across the world is the difficulty of changing behaviors. Building a stable health system that provides quality products and services to its beneficiaries can only go as far as the patients’ willingness to trust that system. There may be clinical evidence that proves the health benefits of a given drug or device, but can that evidence compete with history, cultural norms, stigma, trust, and many more behavioral and societal pressures that often preclude widescale adoption?
Open Source Series Part 1: What is Open Source?
Here at DAI we rely on software applications and data systems for our everyday work. From internal chat applications, to business intelligence software, to online data collection platforms, technology systems enable us to do our work more efficiently and effectively. But when working on international development projects, we must consider other factors such as access to desktop versus mobile devices, computer processing power and storage, levels of technical acumen, and maybe most importantly, cost.
GeekFest 2017: Talking Open Source Design, Makerspaces, and Global Supply Chains with Jessica Berlin
Welcome to GeekFest 2017, a series of interviews featuring ICT4D thought leaders. Our goals for #GeekFest2017 are: to highlight the people and organizations who are pushing the field in new directions, to feature their work and show how it’s different or new, and to support the overall growth of the ICT4D community.
This week I’m speaking to Jessica Berlin, the co-founder of the MakerNet Consortium and founder and Managing Director of CoStruct based in—you guessed it—Berlin, Germany. Before taking the leap as an entrepreneur, Jessica worked for a number of German and U.S. government organizations and development agencies as well as nonprofits in Africa, Asia, Europe, and North America—experiences that inspired her to start her own company to create new programs, provide innovation strategy consulting, and build public-private partnerships to advance business and tech innovation in emerging economies.
5 Things to Consider When Doing Mobile Data Collection
This is a guest post by Nafessa Kassim, Director of Business Development, and Al Ismaili, CEO and Co-Founder of Bamba, a mobile data collection company in Nairobi, Kenya.
Development organizations now have a plethora of mobile data collection tools at their disposal, and choosing between the various options available can often seem like a daunting task. But even after finding the right tool, it is imperative to think through and address the most common challenges that arise in the mobile data collection process. In the last five years of helping development actors integrate mobile phones into their data collection processes, we’ve identified five challenges they run into most often.

Photo credit: David Staten
HCD in the Field: Trading Counterfeit Rupees for Real Insights with Farmers in Nepal
This is a guest post by Meredith Perry, Innovation Specialist with DAI’s Center for Development Innovation project.
My colleague pressed $1,000 in visibly fake Nepali rupees into the hands of each farmer, inputs dealer, and agricultural entrepreneur. Then, she grandly opened the doors to our ersatz haat bazaar (an outdoor, rural marketplace) and instructed them to, “Pay what you would be willing to spend on the products.”

Inside the Data-Driven Farming Prize’s “haat bazaar.” Yes, we know inside makes this an oxymoron. Photo by Kathaharu Studios.
For two hours, the din associated with an actual marketplace poured out of a Kathmandu conference room. The Data-Driven Farming Prize’s 13 finalist teams became sellers straining to attract prospective buyers from among the invited participants. But how did data analysts, graduate students, and entrepreneurs transform into wily hawkers? Why was a simulated haat bazaar a Data-Driven Farming Prize activity?
Lean Design for Development: A Practical Approach to Human-Centered Design
Bilateral donors and foundations continue to look to digital tools to innovate. Why innovate? Given the intractable nature of many development problems, innovation speaks to the desire for different results, to try something new, or to apply something old in a new context or in a new way. Digital tools hold the promise that a program can leapfrog traditional development pathways, amplify impact, and create real game-changers in people’s lives. One way to increase the possibility of success in deploying any digital tool is to follow the principles for digital design - particularly design with the user. Human-centered design (HCD), and its close cousins, co-creation, design thinking, and lean startup methods, can serve not just as an activity but as a process for effective creation, iteration, and implementation.
6 Things I Have Learned About Delivering an Introductory ICT4D Training
On the ICT team we wear many hats and have many responsibilities. We are technical specialists who support our company’s global development projects in the design and use of digital solutions. We are evangelists who teach others about the potential of digital technologies to enhance and sustain the impact of development programming. We are thought leaders who answer strategic questions about where digital development is as a technical field and where it might be going. These are the aspects of our work that often appear in our blog posts.
But another hat we wear is as trainers: It is our responsibility to familiarize our projects and clients with the fundamentals of digital design and to equip colleagues with practical knowledge on how to effectively integrate digital programming into their work so they can design and deliver their own digital programs. Since joining the team some 19 months ago, I have had the chance to train 100+ people in three countries on the fundamentals of digital development. Below are my biggest takeaways on how to ensure that participants get the most out of their training.

Iterating Digital Insights with Cambodian Civil Society Groups
Civil society organizations (CSOs) play a critical role in public life: understanding citizens’ daily challenges, providing services to address those challenges in the short-term, and pursuing long-term policy solutions. In Cambodia, there are hundreds of CSOs, but a wide variability in management capacity, technical capability, and staffing has given rise to domestic and international organizations that exist to help these CSOs carry out their important social role more effectively.

Interviewing the director of a Cambodian CSO for Member Insights.
Domestically, the Cooperation Committee for Cambodia (CCC) functions as a membership association for Cambodian civil society organizations, and provides training, research, and technical assistance to roughly 170 member organizations. From the international community, there is a wide range of donors, foundations, and nongovernmental organizations (NGOs) that support Cambodian CSOs, including USAID’s Development Innovations (DI) project. DI helps local CSOs, technology companies, and social enterprises design and use new technologies to address Cambodia’s development challenges.
The Viral Success of Horticulturalist Chat Groups: An Uzbek ICT4Ag Case Study
In the typical way things happen at large global firms with highly decentralized project management, I first learned about the exceptional digital work being done by DAI’s U.S. Agency for International Development-funded Agricultural Value Chain Activity in Uzbekistan project (AVC) through an email referenced in a meeting about something totally different. I took a photo of the email—true story, I even sent the shot to my colleagues I was so excited—followed up with the listed contacts, and two weeks later was having a fascinating conversation with two dynamic Uzbek colleagues, Kamil Yakubov and Sardor Kadirov, who manage AVC’s digital initiatives.
Women in Agritech: Profiles from Ghana
This is our latest piece on Kosmos Innovation Center (KIC), a DAI-supported initiative that helps young entrepreneurs build tech startups that address challenges in Ghana’s agricultural industry. Find out more about this project in previous Digital@DAI posts here and here.
The KIC works at the intersection of three fields traditionally dominated by men: agriculture, entrepreneurship, and technology. In response, the KIC is tapping into the potential of young female entrepreneurs. Below we profile some of the women co-founders playing a key role in developing business concepts, designing technology products, and pitching to potential investors.
9 Lessons on Digital Design from ICT4D 2017 in Hyderabad
I spent the last week at the 2017 ICT4D conference in Hyderabad, a four-day feast of presentations, discussions, and panels on how international development organizations are using new technologies in their work overseas.

What Bike to Work Day Tells Us About Open Data
More than 17,000 Washington, D.C.-area residents are commuting by bicycle today, as part of the 17th annual Bike to Work Day. The event’s rising popularity parallels the region’s growing investment in bicycle infrastructure and multimodal transportation. This is a positive trend, particularly for those of us who want cities and urban areas to provide safe, convenient, and diverse transportation options for all residents. But is there a larger message for international development? What can Bike to Work Day tell us about the importance of open data for civic engagement?
How to Run an Electronic Cash Transfer Program: A Kenyan Case Study
Working on an ICT team can sometimes feel like being the Morpheus of the development world—all we want to do is show development project teams that digital tools can unleash immense potential. So we try our best to sneak ICT elements into projects in any way possible: short blurbs in project proposals, ICT strategy documents while on technical assignments in the field, or straight-up bribery. Whatever it takes to sugarcoat the red pill. So imagine our surprise when we were asked to meet with a DAI-led project that already has multiple ICT tools integrated into its workflow: the Kenya Hunger Safety Net Programme Phase 2 (HSNP2), funded by the U.K. Department for International Development.

GeekFest 2017: Exploring Mobile Money and Women’s Financial Inclusion with Yasmin Bin-Humam
Welcome to GeekFest 2017, a series of interviews featuring ICT4D thought leaders. Our goals for #geekfest2017 are: to highlight the people and organizations who are pushing the field in new directions, to feature their work and show how it’s different or new, and to support the overall growth of the ICT4D community.
In this installment, I’m picking the brain of my own sister, Yasmin Bin-Humam, a Financial Sector Specialist at the World Bank Consultative Group to Assist the Poor. Yasmin is establishing a community of practice focusing on solutions to improve women’s access to financial services, such as mobile and digital services.
Takeaways From F8: It’s Zuckerberg’s World—We’re Just Living In It
F8, Facebook’s annual conference, was my first trip to Silicon Valley—I’ve been to the Silicon Wadi in Israel and the Silicon Savannah in Kenya, but never had I stepped foot where it all began. It was the perfect sort of baptism by fire into the ethos of the place that brought us semiconductors, personal computing and smartphones: a gathering where the future is dreamed up by developers and defined by technology’s limitless potential. It was wild.
I’ll outline below a few of the innovations that are particularly relevant to the work we do, and then make an argument for why the practice of ICT4D is more important than ever.
First Contact with the Planet API and NodeJS
We love remote sensing here at DAI and luckily for us, satellite imagery APIs are starting to pop up all over, like springtime flowers. One of the most prominent imagery providers is Planet, a small company with lofty service and product offerings for remote sensing. Planet builds and launches small satellites that image the entire world every day. It provides access to that imagery through a web platform, and it gives developers access to its data through a web API.
Meet Honduras's Innovation Community
Chronogram of the 2016 Honduras Startup accelerator from hondurastartup.com
In December 2016, I spent a month in Honduras helping launch the new USAID Local Governance Activity and, replicating some work I did in El Salvador last year, I decided to get to know the innovation and technology community. Why?
DAI is currently launching four new USAID-funded projects in Honduras: local governance, a justice & human rights project, an environmental governance project, and the new school-based violence prevention project. My goal in writing this piece is the same as it was when I wrote Hey USAID, Want to Promote Innovation?: to get those new projects to think creatively about how to achieve their goals.
Digital Insights Rwanda: How Do Rural Youth Use New Technologies?
In early March, I spent a week in Rwanda building a profile of how young people in rural areas use media and technology and interact with rural financial institutions (RFIs). With the help of the Rural Youth Agribusiness Forum (RYAF), we interviewed 116 young people (aged 17 to 34) in a ring of towns and villages outside the capital, Kigali.

A Digital Insights interview in a rural area outside Kigali.
SXSW 2017: The More Trends Change, the More They Stay the Same
The annual South by Southwest Interactive Music and Film Festival with all of its thought-provoking panels, workshops, keynote speakers, and booths demonstrating the latest gizmos, gadgets, applications, and trends has come and gone—and for the second year, I was in attendance to make some sense of it all.
Jhatkaa: Tech-enabled Citizen Advocacy in India
Our top post of 2016 was my interview with Avijit Michael, the director of Indian citizen advocacy organization Jhatkaa. In his interview, Avijit mentioned they had created a tool for citizens to report local issues via WhatsApp. Needless to say, we were intrigued. So, in the spirit of investigative journalism, we sent one of our staff members to India to find out more.
Digital Insights Bangladesh: How Urban Youth Stay Connected
It’s late January in Dhaka, Bangladesh, which means I’ve managed to avoid the usual heat and humidity, but the bustle and throng are just what I’d expect of one of South Asia’s largest cities. Even though I grew up in India, I’ve never had the chance to travel to its sister republic to the east. And yet, all at once, everything seems familiar—the cars, the noise, the smells. My guide through the city is Ontiq Dey, an eager young graduate student of economics and a seasoned data collector. He and four of his classmates are DAI’s street team for our first-ever Digital Insights study in South Asia.

Digital Insights data collectors gathering information from students in Mymensingh.
Top 5 Social Media Blogs: How & Why ICT4D Pros Should Think Like Digital Marketers

Back in the day, when I was but a young ICT4D practitioner trying to figure out how to get hundreds of thousands of Somalis to open and read text messages about democracy and governance from a tiny startup’s office in Palestine, I developed a weird habit of obsessively reading fast-moving consumer good product mobile marketing blogs. Why? These commercially focused blogs had super insightful guidance on how to structure mobile campaigns and get users to open, read, and act upon messaging content—because at the end of the day, selling good governance isn’t that different from selling individual shampoo packets. Both take targeted, entertaining and value-added content, and timing to have the most impact, and because the advertising firms servicing large multinationals had a lot more money to invest in getting the art of the mobile campaign right, I figured, why not poach their best practices for the social sector? Fast forward seven years, and I’m doing the same thing but for Facebook.
I Made a Facebook Chatbot (And You Can, Too)
When I first heard that Facebook Messenger was introducing chatbots, I immediately thought back to junior high summers. Back then I was spending a lot of time in my parents’ basement on the computer–safe from harmful things like sunshine and other people–getting into flame wars with people on IRC that (more often than not) turned out to be chatbots. Not my greatest summer. Fast forward some 20 years, and chatbots are back with a vengence, this time with a significantly improved value proposition: (near) last mile access to native language information and services.

Our Digital Insights research in Indonesia, Honduras, and Palestine emphasized the popularity of Facebook and FB Messenger in the marginalized communities where DAI and other development implementers work. In Indonesia, 77 percent of the people we interviewed said they use Facebook on their phones; in Palestine that number was 95 percent. In Honduras, 80 percent of our respondents across urban and rural areas said they use Facebook. If development projects want to reach people with information and services, we must meet them on the platforms where they already spend time: in more and more cases, as access to the internet, smartphones, and social media grow, that means on Facebook. (No, not exclusively and not in all instances. read our Indonesia post, and see which social media messaging app is king there.)
Crowdsourced Data Collection Provides On-the-Ground Insights
At the end of 2016, we published a post on the digital data collection sector. In 2017, we’re delving deeper into this growing sub-field of ICT4D with interviews, technology reviews, and guest posts. We’re kicking things off with a piece from our friends at Findyr who specialize in gathering insights from emerging markets using mobile-enabled, trained data collectors from the field. Kelsey Buchbinder is a Business Development Associate at Findyr.
Unemployed? Stop Looking for a Job and Create One—Insights from INC Monterrey
Guest blogger Caity Campos is a specialist in our youth and workforce development unit. Here she reviews the recent Innovate Network Create (INC) Monterrey conference, a gathering of global entrepreneurs from a variety of disciplines.
Finally, a conference that wasn’t boring, cliché, or overly esoteric. The Innovate Network Create (INC) Monterrey, held in November was exciting, innovative, and inspiring. Lest you think I am being hyperbolic, let me share some conference highlights:
Remote Sensing Part 4: The Everest of Satellite Conferences, SatSummit 2017
We reached the summit of satellite conferences this week! This is the fourth post in our remote sensing series. See part 1, part 2 and part 3.
#SatDiversity and #FatData are two hashtags I did not expect to see blaring across the screen when I attended the SatSummit conference this week. These bold declarations are something new: a compression of expression, capturing with perfect brevity the major themes of a fledgling tech space on the cusp of bringing real change almost as quickly as the terabytes of data that rain down to Earth from satellites bearing the names of these space-technology pioneers. Here’s some key takeaways from the event.
More Data, Less Risk: Innovators Chart a Path to Financial Inclusion
The phrase “Catch-22” was originally coined to describe a paradoxical situation that someone is unable to escape from because of contradictory rules or regulations. Think, for example, about the recent graduate who is unable to obtain a job because he or she does not possess any previous work experience, yet cannot gain any work experience because he or she cannot get a job. Fortunately, as tends to be the case with graduates who persist, compromising expectations and demands, eventually someone takes a chance, giving them the benefit of the doubt, and chooses to invest in their potential.
Remote Sensing Part 3: Identify Healthy Vegetation From Space
DAI’s excitement about the upcoming SatSummit is approaching perigee levels, with the conference less than one week away! This is Part 3 of our Remote Sensing Series. In case you missed them, here’s Part 2 and Part 1.
You could live a perfectly fulfilled life while taking for granted all the colors that appear in the natural world. However, when you ask “why?”—a fascinating level of complexity is revealed, and this is especially true for the colors of nature: green forests, blue skies, red roses, golden sunsets.
Remote Sensing Series Part 2: Landsat is the Stalwart of Satellite Imagery Platforms (and it’s Free!)
DAI is in a stellar mood about the upcoming SatSummit in Washington, D.C. Part 1 of the remote sensing series can be read here.
Some incredible things were happening in the United States in 1972: Bill Withers’ “Lean on Me” was the No. 1 song on the radio; the first “Godfather” film was released; and NASA launched the first in a series of satellites designed to provide consistent and reliable coverage of the earth’s land cover. The platform—the Earth Resources Technology Satellite or ERTS-1—was developed in partnership with the U.S. Geological Survey (USGS), which agreed to handle the storage, archiving, and distribution of the data products. The second satellite, eventually renamed Landsat 2, launched in 1975, operating in parallel with ERTS-1 for a few years until the original satellite was decommissioned in 1978.
Situamos a la Ciudadanía en el Centro del Proceso de Diseño en Guatemala
This post is also available in English.
Actualización: Somos Chiantla ahora esta disponible para descarga a dispositivos Android. Una nueva publicación cubre su lanzamiento.
A finales de 2015, el proyecto USAID Nexos Locales recibió una solicitud novedosa. Fue enviada por Carlos Alvarado Figueroa, que acababa de ser elegido alcalde de Chiantla, un municipio de 75.000 habitantes en el altiplano occidental de Guatemala. Alvarado había sido elegido por su plataforma de transparencia presupuestaria y auditoría social, y formó parte de una ola de reformadores de buena gobernabilidad que fueron elegidos después de la revelación del escándalo denominado La Línea, que envió a prisión el Ex Presidente Otto Pérez Molina y la Ex Vicepresidenta Roxana Baldetti.
What Good Is the Internet of Things to People Who Don’t Have the Internet?
As I write this, the annual Consumer Electronics Show has just wrapped up in Las Vegas, having introduced an allegedly eager public to smartphone-enabled hairbrushes, Bluetooth-capable vibrating hotpants, and refrigerators that tweet when you’re running low on soy milk. This is what marketing departments call the Internet of Things (IoT): devices that are networked for sensing, control, and/or coordination. Under the stifling blanket of hype, though, new platforms, network protocols, and data repositories really are enabling applications of value, in addition to the tweeting kitchen appliances which, one hopes, will stay in Vegas.
GeekFest 2017: Q&A with Ian Schuler, CEO of Development Seed

Welcome to Geekfest 2017, a series of interviews featuring ICT4D thought leaders. Our goals in launching #geekfest2017 are: to highlight the people and organizations who are pushing the field in new directions, to feature their work and show how it’s different or new, and to support the growth of the ICT4D community.
We’re kicking things off with Ian Schuler, the CEO of Development Seed, one of the lead organizers and sponsors for the upcoming SatSummit.
Hiring ICT Staff (Or, How to Get 500 IT CVs Without Really Trying)
Kabul, 2016. I’d been here before: a cold cup of Nescafe and stack of overly formatted CVs on the table next to me, an over-worked HR officer slow-blinking at me from across the room in subtle panic. Of the 35 CVs in the stack, culled from hundreds submitted online, only two had any mention of ICT experience—the rest were full of network engineering degrees, Oracle and Microsoft certifications, and years and years of experience managing IT networks and project systems. If I had been looking to hire IT staff, I would have been spoiled for options—but I wasn’t. I was trying to hire an ICT officer, and it was almost impossible. Just as it had been in Cambodia, Jordan, and Senegal. Why, oh, why was hiring ICT staff so hard, and what could we do about it?
Digital@DAI Year in Review: Top Five Posts of 2016
That’s a wrap for 2016, folks. We launched this blog in February with a sense of curiosity and caution, unsure who would read it—or if it would be read at all. Since then, we’ve grown steadily to more than 2,000 page views a month, collaborated with colleagues throughout the ICT4D ecosystem to host 12 guest author posts, and had the privilege of teammate John DeRiggi being interviewed by the BBC’s program “Click,” about his post on Machine Learning in Afghanistan.
We’re Putting Citizens at the Center of the Design Process in Guatemala
Esta entrada también está disponible en español.
Update: Somos Chiantla is now available for download to Android devices. A follow-up post covers the launch event and next steps in development.
Back in late 2015, the Nexos Locales project in Guatemala received a novel inquiry. It was from Carlos Alvarado Figueroa, who had just been elected mayor of Chiantla (CHEE-ahn-tlah), a municipality of 75,000 in the Western Highlands, and he had an idea. Alvarado had been elected on a platform of budget transparency and social audit and was part of a wave of good governance reformers that swept into office on the heels of the Línea corruption scandal, which saw both President Otto Perez Molina and Vice President Roxana Baldetti jailed. He wanted DAI’s help to design and develop a mobile tool to give the citizens of Chiantla (Chiantlecos) better access to municipal government. In particular, he wanted to give Chiantlecos an easy, transparent view on how his government was allocating and spending money, facilitating social audit and giving citizens the ability to more easily communicate with his administration. So, the project called me, and I called the Mayor.
Next Steps: Making Countering Violent Extremism Approaches More Rigorous
This is a guest post by a friend and colleague of the DAI ICT Team, Ben Dubow. Ben is a partner at Omelas, a firm that works to bring together data scientists, software engineers, and counterterrorism experts to defeat violent extremism. Debuted at the annual meeting of the Nordic Council of Ministers, Safe Cities, Omelas currently has operations in Europe and the Middle East. It was co-founded by Ben, Evanna Hu, and Bjorn Ihler.
I started my career by conducting threat analyses of suspected jihadists. I’d trawl their online profiles and then use a mix of instinct and experience to decide what to include. It made sense that sharing a post from a Taliban website signaled radicalization. It made sense that following a jihadist preacher signaled the same. It made sense that liking a Facebook page for bacon lovers signaled some apprehension about fundamentalism. But making sense was the extent of the proof we had.
Remote Sensing Series Part 1: The Foundations and Applications of Remote Sensing
This is the first in a series of posts about remote sensing. DAI is entering an orbit of excitement about the upcoming SatSummit on January 31!

Origins of Remote Sensing
One day in 1800, German-born British citizen and musician-turned-astronomer, Sir James Herschel was doing something we’ve all found ourselves doing on lazy Sunday afternoons: He was playing around with a prism, investigating the temperature differences between the bands of colorful light that splay out in this familiar natural sequence:

Herschel placed a thermometer to the left of the red band and found invisible infrared light.
Mobile Data Collection: A Sector in Flux
In recent years, mobile surveys and data collection capabilities have increased alongside rapidly expanding mobile phone penetration in the developing world. And with this trend, there has been a proliferation of small firms that have entered this space. At DAI, we realize that by allowing us to quickly capture hard-to-gather data and conduct surveys across our portfolio, new tools can change the way we execute development projects as well as win new business.
Crowdsourcing Ideas—The Challenge Fund Model for Innovation
I apologize for using the word “innovation” in the title of this post. I know… I work in ICT4D and I’m supposed to be a champion for innovation in all its forms. The truth is, for me, the word has nearly lost all its meaning. Innovation is easily one of the most overused and least-understood words favored by businesses, academia, and yes, international development agencies. So instead of writing a post on how we can “promote innovation,” per se, I prefer to write about how we as development practitioners can use promising models to source, finance, and apply new solutions—be they digital technologies, products, or processes—to development problems based on open competition, collaboration, and evidence.
4 Things I Learned at MIT’s TechCon
This past week I attended TechCon 2016, co-hosted this year by MIT and the U.S. Agency for International Development (USAID). TechCon is the annual gathering of the Higher Education Solutions Network, a partnership between USAID and top universities to harness the academic power, passion, and curiosity of students, researchers, and faculty to solve global development challenges. Spoiler alert: it was GREAT. It’s easy to forget in the day-in, day-out of ICT4D work that “technology” has a far broader remit than the work we as ICT4D practitioners do in it. Engaging with researchers and academics conducting research far outside my normal scope awakened a sense of real and joyful curiosity I hadn’t felt in awhile. So beyond this humble reminder, and that Boston in autumn is truly glorious, here’s a few other things I learned at TechCon.
Counting People is Hard: Biometrics can Help
This is a guest post written by Ben Mann, a development specialist at DAI with a wide range of interests. He is a policy wonk; water, sanitation, and hygiene (WASH) technical expert; ICT enthusiast; and general advocate for improved use of data and visualizations. Follow Ben on twitter @bhmann
One of the core functions of an effective monitoring and evaluation (M&E) system is the ability to accurately count things. Depending on your M&E strategy, you may be counting the number of schools built in a district, number of boreholes functioning in a region, or the number of microloans given to farmers in a cluster of villages. From my experience designing and operationalizing M&E plans for a range of private and bilaterally funded programs, counting people is by far the hardest and most complex to do—especially when you are trying to observe and record information on the same people over an extended time.
Hey USAID, Want to Promote Innovation?
Earlier this month I had the good fortune to attend the Global Accelerator Network’s (GAN) annual Rally in Denver, Colorado. GAN includes 70 startup accelerators in 100 cities across six continents.

GAN CEO Patrick Riley and the managing directors of startup accelerators at the GAN Summit 2016
Should Big Data Be Open Data?
This is a guest post by Michelle Kaffenberger, Applied Research Consultant, and Bill Kedrock, Independent Consultant. The post uses Nigeria smallholder farmer data collected through the Growth Enhancement Scheme as the backdrop for a set of initial principles to guide those weighing the pros and cons of opening big data.
We propose that when considering whether big data should be made open, decision makers should apply a litmus test including at least the following three questions, and likely many others according to the specific context of the data.
App-a-Thon 2016: Viber for Development
As we’ve ramped up our Digital Insights work over the last few months, we’ve had the opportunity to talk with people around Africa, Asia, Latin America, and the Middle East about the digital tools they use to stay in touch with each other and the world around them. These conversations have reminded us that we have to work hard to stay on top of the growing number of messaging apps on the market today, as what was popular six months ago might no longer be today. “App-a-Thon 2016” is our way of quickly immersing ourselves in different messaging apps to learn about their functionality, look, and feel. How does it work? The entire DAI ICT team signs up for a platform, and for one week, we use it to chat with each other, send images and video, and explore the quirks and features of the app.
So far, we’ve covered WhatsApp, Facebook Messenger, Telegram, kik, LINE, and BBM. This time around we’re checking out Viber.
Geeks Like Us: How Academic Research Can Help us Create Better ICT Programs
In a not-so-distant past life, I was at the PeaceTech Lab, a spin-off from the U.S. Institute of Peace. For the most part, the Lab executes in-country technology and media projects, but one vestige of its parent organization’s think tank legacy is the Blogs & Bullets project—a research initiative done in partnership with some of the wonkiest political science and data analysis geeks from American University, George Washington University, and Stanford University. As I’ve made my transition into a full-time ‘do tank’ like DAI, it has become easy to dismiss (or forget) the somewhat esoteric pursuits of our friends in academia. But with the release last week of the latest installment in the Blogs & Bullets series, I was reminded just how important the work of the Ivory Tower is to advancing our understanding of the role of ICT in creating real world change in the places where we work.
Have You Read the 2016 Digital GAP Act?
Update: Since I wrote this, Congress.gov removed the text of the bill. It’s now pasted at the bottom.
Have you read the Digital Global Access Policy (GAP) Act?
If you’re an ICT4D practitioner, you should.

The bill was just passed in the House and is speeding toward a Senate vote. So, what’s it all about? In short, it enshrines the growth of affordable internet access as a tenet of U.S. foreign policy by promoting:
View archived posts.