Data Management Series Part 2: Don’t Let Your Data Get Dusty
This post is one of a series of posts on Data Management.
Aug 31, 2017
So, after reading last week’s blog, you’ve developed the world’s most robust monitoring, evaluation, and learning plan. You just conducted a multi-tier baseline assessment, validating your data by triangulating data points through five different surveying tools and are excited to dig in to multivariate regression analysis. But wait! First we need to talk about data storage and management!
In the international development world, an all-too-familiar sight is binders of data sitting idly on shelves in rural government offices. We all acknowledge that there are much better ways to store and maintain our results. However, many organizations only move one or two steps up the ladder: from paper and pen to .xlsx or .csv files on a laptop. While this may enable you to conduct the minimum analysis needed to satisfy your donor in an annual report, does it really maximize the value of the data we collect?

Along the data management chain, all links are equal in importance. However, storage is often the weakest. Revisiting our commodity analogy from the first post in this series: Would you rather put all of your oil in an array of small, paper cups with lots of holes or a large steel barrel with reinforced sides? A good data storage and management plan should enable you to do the following things:
- Store your data without fear of loss.
- Map your data model without inaccurate or inconsistent relationships.
- Clean your data without risk of versioning mishaps.
- Secure your data without compromising flexibility.
When it comes to storage, the following considerations are essential when designing a broader data management system:
Local vs. Cloud Hosting
One of the first decisions that has to be made regarding data storage is whether data should be stored on local servers or in the cloud. Generally speaking, cloud storage tends to be more cost effective, requiring less up-front costs. It also requires less maintenance (or none at all) as all updates and security patches are handled by the service provider and are included in the cost of service. The cloud also offers major advantages for scalability (purchasing more storage space is simple) and security, as cloud storage providers often employ advanced, industry standard security protocols, and data is automatically backed up in the cloud. On the other hand, local storage offers the advantage of speed and uptime for projects working with poor internet infrastructure. Cloud storage certainly carries a lot of advantages, but the choice may be made for you if reliable cloud services aren’t offered in your locale.
Database Types
OK, so you know where you want to store your data, you should be all set to upload your data and get started with regression analysis, right? Wrong. You also have to consider what type of database you will be using. The main distinction here is between relational and non-relational databases. SQL and Oracle are relational databases and are characterized by multiple data ‘buckets’ that are linked to one another by relationships that require a link or a ‘key.’ Non-relational databases, such as MongoDB, store data without explicit structures and mechanisms to link data between buckets. While the pros and cons of both are many, this choice typically boils down to the fact that relational databases make it easy to structure and combine datasets, but do not scale horizontally as well as non-relational databases.
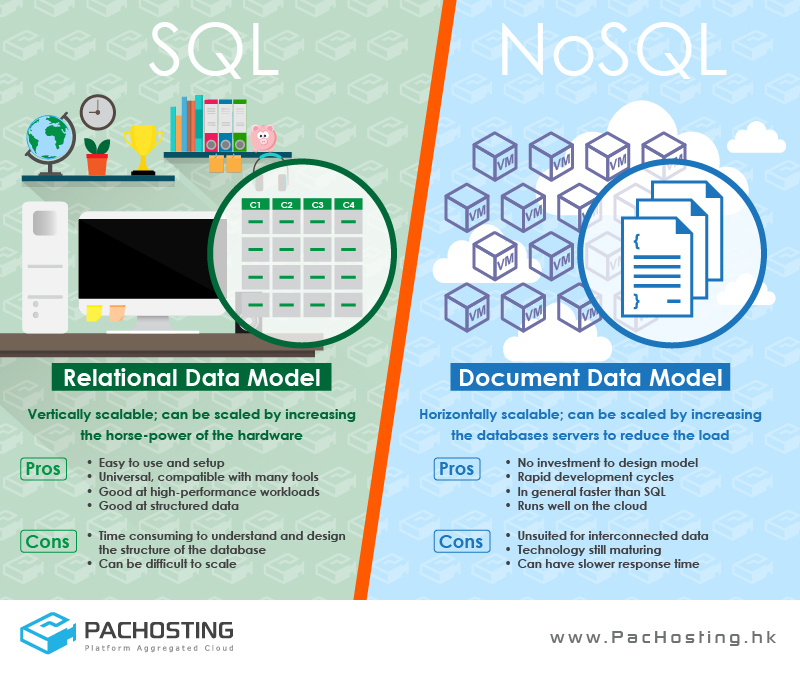
Relational (SQL) vs. Non-Relational (NoSQL) databases. Photo credit: PACHOSTING Platform Aggregated Cloud.
Cleaning
Anyone we know who has ever worked with moderately large datasets will almost certainly tell you the same thing if you were to ask them what aspect of their work is the most time-intensive. “Don’t underestimate the time it takes to clean data” they are likely to say. Maybe you’ll get lucky—maybe the people collecting the data at your organization work with advanced collection tools and make no data entry errors such as spelling mistakes, or using a number in place of a text, or enter GPS coordinates of 0 instead of none at all for a data point without a location (you would be surprised to see how many schools appear to be in the Atlantic Ocean off the coast of Ghana). As is the case for all categories, a number of tools—both manual and algorithmic—exist that can remove duplicates, reformat data points, and correct incorrect data. The tools that we use enable us to perform relatively complicated cleaning or “scrubbing” without needing to have advanced programming skills.
Security
Encompassing all of the categories above, any data management plan must account for security. This means you need server-side security to ensure that no one can access your data without permission. It means internal personal account security, for your system users and data subjects, so their personally identifiable information doesn’t leak into the wrong hands accidentally. There are many tools and approaches to tackle these issues, from data masking and user levels to high level, end-to-end encryption. One of the worst outcomes of any data management plan is compromised data from a malicious source—our plans always account for the resource costs needed to keep our systems and data safe and secure.
Data storage and maintenance can be the most complex element of the data management chain. Beyond these first categories lie a myriad of other considerations that should be planned for at the beginning and will influence your choices for database structures. For a deeper look at these important topics, check out these resources: