Can Regulators Keep up with Artificial Intelligence?
Aug 12, 2021
Artificial intelligence (AI) presents one of the most difficult challenges to traditional regulation. Three decades ago, software was programmed; today, it’s trained. AI itself is not one technology or singular development. It is a bundle of technologies whose decision-making mode is often not fully understood even by AI developers.
AI solutions can help address critical global challenges and deliver significant benefits; however, the technology could lead to unforeseeable outcomes absent clear regulations and ethical guidelines. AI can have damaging repercussions for data privacy, information, and cybersecurity, providing hackers with ways to access sensitive personal data, hijack systems, or manipulate devices connected to the Internet. Self-learning algorithms already anticipate human needs and wants, govern our newsfeeds, and drive our cars. How can we ensure that this technology benefits people widely? If AI and autonomous machines play a crucial role in our everyday lives, what sort of normative and ethical frameworks should guide their design?
The “Black Box” Problem
It is challenging to relate something as technical as AI to robust regulation. On the one hand, most regulatory systems require transparency and predictability; on the other, most laypeople do not understand how AI works. The more advanced certain types of AI become, the more they become “black boxes”, where the creator of the AI system does not really know the basis on which the AI is making its decisions. Accountability, foreseeability, compliance, and security are questioned in this regard.
From approving loans to determining diabetes risk, AI algorithms make strategic decisions. Often these algorithms are closely held by the organizations that created them or are so complex that even their creators cannot explain how they work. This is AI’s “black box”— the inability to see what is inside an algorithm. The reasons for the decisions made by an AI system are not easily accessed or understood by humans, and therefore difficult to question or probe. Private commercial developers generally refuse to make their code available for scrutiny because the software is considered proprietary intellectual property, which is another form of non-transparency.
This problem is exacerbated by the many public authorities that have started using algorithms for making decisions on sentencing, enforcement, and delivering social services to citizens. A study conducted by AI Now suggests that many AI systems are opaque to the citizens over which they hold power. Regulators have already started enacting algorithm accountability laws that curtail the use of automated decision systems by public agencies. For instance, in 2018, New York City passed a local law about automated decision systems used by agencies. The Act created a task force to recommend criteria for identifying automated decisions used by city agencies, a procedure for determining if the automated decisions disproportionately impact protected groups. However, the law only permits making technical information about the system publicly available “where appropriate” and states there is no requirement to disclose any “proprietary information.”
Some experts have suggested making algorithms open to public scrutiny. For instance, the EU GDPR requires companies to explain how algorithms use the personal data of customers’ work and make decisions — the right to explanation. However, since this right has been mentioned in Recital 71 of the GDPR, many point out that it is not legally binding. According to Article 22 of the GDPR, EU citizens can request that decisions based on automated processing be made by humans and not just by computers. Citizens also have the right to express their views and to contest the decision.
Automated systems in recruitment and selection provide another example of AI’s black box decision-making. Many companies have started using a hiring technology developed by the startup HireVue that analyzes job candidates’ facial expressions and voices. Critics have expressed fear that using AI in hiring will re-create societal biases. The algorithm is a property of HireVue, and its functioning and decision-making principles are kept secret from the public.
Regulators have already started tackling these legal problems. The new Illinois Artificial Intelligence Video Interview Act aims to help job candidates understand how hiring tools operate. According to the Act, companies must notify applicants that AI will be used to consider applicants’ “fitness” for a position. Companies should also elaborate on how these systems operate and what characteristics are considered when evaluating candidates. The companies must also enable candidates to consent to the use of automated hiring systems.
Algorithmic bias
In a perfect world, using algorithms should lead to unbiased and fair decisions. However, researchers have many found that many algorithms come with inherent biases. AI systems can reinforce what they have been taught from data, including racial or gender bias. Even a well-designed algorithm must make decisions based on inputs from a flawed and erratic reality. Algorithms can also make judgment errors when faced with unfamiliar scenarios.
This phenomenon leads to so-called “artificial stupidity.” In 2016, ProPublica analyzed a commercially developed system that predicts the likelihood that criminals will re-offend, created to help judges make better sentencing decisions, and found that it was biased against people of color. Though facial recognition is still in its nascent stages, algorithms have been proven to be limited when detecting people’s gender and race. These AI systems were able to detect the gender of white men more accurately than the gender of men with darker skin. Similarly, Amazon’s hiring and recruitment algorithm taught itself to prefer male candidates over females. The system was trained with data collected over a 10-year period that mainly came from male candidates.
Melbourne-based researchers asked human volunteers to judge thousands of photos for the same characteristics and then used that dataset to create the Biometric Mirror. The Biometric Mirror uses AI to analyze a person’s face by scanning it, and later displays 14 characteristics about them, including their age, race, and perceived level of attractiveness. However, this analysis is often false because the AI generates the analysis based on subjective information provided by initial human volunteers. These biases pose challenges, as AI systems can discriminate in unethical ways, leading to societal consequences.
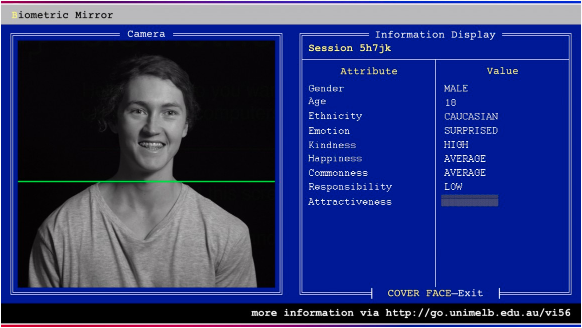
The Biometric Mirror uses an open dataset of thousands of facial and crowdsourced evaluations. Photo credit: Sarah Fisher/University of Melbourne
AI systems have spread disinformation and misinformation. Legitimate news and information are sometimes blocked, illustrating the weaknesses of AI in determining what is appropriate. For instance, Facebook blocked a 1972 Pulitzer Prize-winning photo of a Vietnamese girl because of nudity. The company was accused of abusing its power, and the photo was later reinstated. These examples have led to a growing argument that digital platforms posting news stories should be subject to regulations like those that media firms face.
Deepfakes—computer-generated and highly manipulated videos or presentations—present another significant problem. Some governments have started regulating them, and big tech firms are also trying to control their use. For example, Facebook banned users from using deepfakes to stop disseminating misinformation surrounding the 2020 US presidential election. The problem with this policy was that it did not prohibit all computer-manipulated videos; for instance, the policy did not address a deceptively edited clip of the US House Speaker Nancy Pelosi that went viral on the social network in 2019. Facebook sent the video for review to a third-party fact-checker who rated it as “false” and de-ranked it in News Feeds without removing it.
A particularly Orwellian scenario of algorithmic bias in regulation would require every citizen to get a social score based on a set of values; the score would determine the government services that citizens receive. Every citizen would be trailed by a file compiling data from public and private sources and for those files to be searchable by fingerprints and other biometric features. Under this type of national social credit system, people would be penalized for the crime of spreading online rumors, among other offenses, and those deemed “seriously untrustworthy” might receive substandard services.
We need AI governance frameworks, protocols, and policy systems that ensure inclusive and equitable benefits for all. Government policies need to balance public interests, such as human dignity and identity, trust, nature preservation, climate change, and private sector interests, such as business disruptiveness and profits. As novel business models like fintech and the sharing economy emerge, regulators face a host of challenges: rethinking traditional regulatory models, coordination problems, regulatory silos, and the robustness of outdated rules.
A complex web of AI regulations could impose prohibitive costs on new entrants into the AI market, which would hurt less-developed countries and smaller firms. Global AI talent is concentrated in developed countries and the hands of a few large multinational firms. Imposing cumbersome compliance costs with a robust system of AI regulations could lead to a situation in which only large firms could afford to comply. This challenge reinforces the need to build flexible and dynamic regulatory models to respond to the changes and optimize their impact.
Traditional regulatory structures are time-consuming, complex, fragmented, risk-averse, and adjust slowly to shifting social circumstances, with various public agencies having overlapping authority. On the other hand, a unicorn AI startup can develop into a company with a global reach in a couple of years, if not months. Moreover, AI is multifaceted and transcends national boundaries. Since there are no international regulatory standards, coordinating with regulators across borders becomes imperative.
The modern regulatory models are innovative, iterative, and collaborative. They rely on trial and error and co-design of regulations and standards and have shorter feedback loops. Regulators can seek feedback using many “soft-law” innovative instruments such as policy labs, regulatory sandboxes, crowdsourcing, codes of conduct, best-practice guidance, and self-regulation. Soft-law instruments accommodate changes in technology and business models and allow regulators to address issues without stifling innovation.
Modern regulatory systems use the ecosystem approach—when multiple regulators from different nations collaborate with one other and with those being regulated. Such systems can encourage innovation while protecting consumers from potential fraud or safety concerns. Private, standard-setting bodies and self-regulatory organizations also play key roles in facilitating collaboration between innovators and regulators.
One example is the Asia-Pacific Economic Cooperation (APEC) forum through the Cross-Border Privacy Rules (CBPR) system, which helps to foster trust and facilitate participants’ data flows. A key benefit of the APEC regime is that it enables personal data to flow freely even in the absence of two governments that have agreed to recognize each other’s privacy laws as equivalent formally. Instead, APEC relies on businesses to ensure that data collected and then sent to third parties either domestically or overseas continues to protect the data consistent with APEC privacy principles. The APEC CBPR regime also requires independent entities that can monitor and hold businesses accountable for privacy breaches.